# 一、JDK
官网 Java 下载:https://www.oracle.com/java/technologies/downloads (opens new window)
# JDK、JRE、JVM
JDK (Java Development Kit) Java开发工具包
JRE (Java Runtime Environment) Java运行环境
JVM (Java Virtual Machine) Java虚拟机
JDK是整个Java的核心,包括了Java运行环境JRE、Java工具和Java基础类库。
JRE是运行Java程序所必须的环境的集合,包含JVM标准实现及Java核心类库。
JVM是整个Java实现跨平台的最核心的部分,能够运行以Java语言写的程序。

运行最小环境:JRE;
开发最小环境:JDK。
# 二、JVM
# JAVA跨平台
Java的跨平台性,其实是取决于JVM的跨平台性。JVM是Java跨平台特性的核心支撑。
同一段代码,在编译后的字节码都是一样的。JVM的作用就是去解释和运行这么字节码文件(.class文件)。在不同的操作系统,会有不同的JVM。所以Java才可以一次编译,到处运行。

# JVM生命周期(类加载过程)
JAVA即是编译型语言,又是解释型语言。
程序源代码(java文件)经过编译器进行编译处理,转换为JAVA字节码文件(class文件)。
JAVA虚拟机(JVM),它的作用是将字节码进行解释和运行——解释为计算机识别的机器码(二进制01010010),再在计算机上运行。
在JVM读取到字节码文件后,调用到哪个类,才会加载该类。经由类加载器(ClassLoader)进行加载,在内存中生成一个代表该类的class对象作为访问入口。
在加载过程中,需要经过验证、准备、解析、初始化后,再进行类的使用。
验证:对字节码文件进行正确性校验。
准备:给类的静态变量分配内存,并赋值默认值。
解析:将符号引用替换为直接引用。例如把静态方法替换为指向数据所存内存的指针。
初始化:对类的静态变量赋初始值,并执行静态代码块。
最后当类方法调用结束,进行卸载。经由垃圾回收器进行垃圾回收,回收那些不在有任何引用的内存。
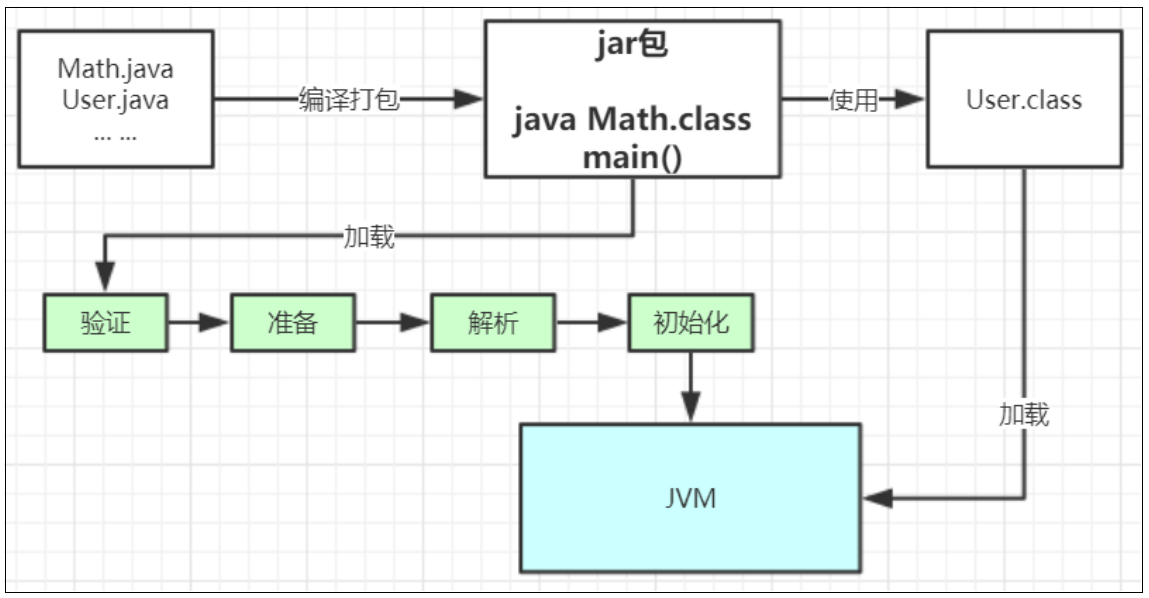
# 类加载器ClassLoader
JVM有三种预定义类型的类加载器:
- 引导类加载器(Bootstap):由C++实现,负责加载支撑JVM运行的核心类库(位于JRE的lib目录下的所有包)。
- 扩展类加载器(ExtClassLoader):负责加载支撑JVM运行的扩展包(位于JRE的lib目录下的ext目录)。
- 应用程序类加载器(AppClassLoader):负责加载classpath路径下的类包。
- 自定义类加载器:可以自定义,创建类加载器。需要继承(extends) java.lang.ClassLoader类,重写
findClass()空方法。
类加载器之间的关系:
- 自定义类加载器的父加载器 ——》 是 AppClassLoader
- AppClassLoader的父加载器(parent属性)——》 是 ExtClassLoader;
- ExtClassLoader的父加载器 ——》 是 null(即引导类加载器)
# 双亲委派机制
原理:
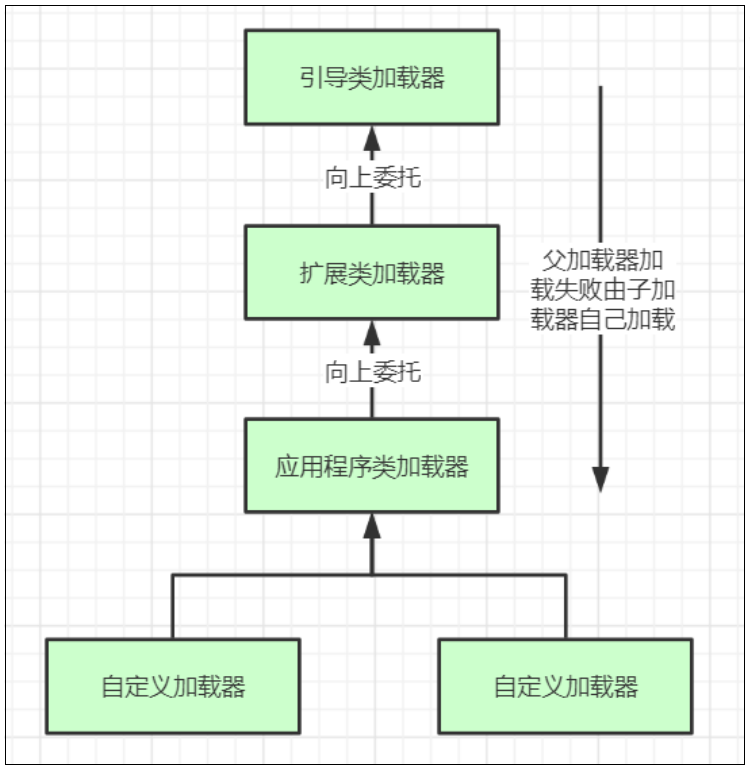
ClassLoader类的loadClass()方法,实现了双亲委派机制。简单说就是在加载类时,先向上找parent 进行加载,没有再向下自己找。
当调用classLoader.loadClass方法进行类的加载,首先由应用程序类加载器(AppClassLoader)进行加载。
先判断是否加载过该类,若加载过直接返回;若无则判断是否有父加载器parent。
即AppClassLoader 向上委派 扩展类加载器(ExtClassLoader)进行加载。
而ExtClassLoader 再向上委托 引导类加载器进行加载。
若引导类加载器在自己的类路径下找到该类,则直接返回该类;若无则再向下回退至ExtClassLoader 进行查找。
若ExtClassLoader 在自己的类路径下找到该类,则直接返回该类;若无则再向下回退至AppClassLoader进行查找。
目的:
设计双亲委派机制,可以保证沙箱安全机制,防止核心API库被篡改;
可以避免类的重复加载,保证被加载类的唯一性。(父类若加载直接返回,不用子类再加载)
打破双亲委派机制:
重写类加载方法loadClass()方法,实现自己的加载逻辑,不再委派给双亲进行加载。
# 对象的创建过程
对象在内存中存储的布局分为了三块区域:对象头、实例数据、对齐填充。
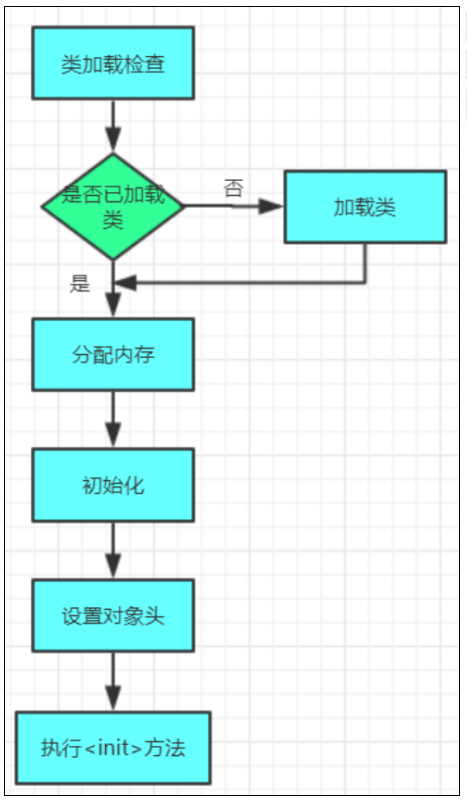
对象的创建过程:
类加载检查——》分配内存——》初始化——》设置对象头——》执行init方法
- 类加载检查:当执行new指令,先去检查该类是否已被加载、解析、初始化;
- 分配内存:JVM为新生对象从堆中划分分配内存;
- 初始化:将分配到的内存空间初始化为零值;
- 设置对象头:存储类的元数据、对象的哈希码、GC分代年龄等对象自身的运行时数据;
- 执行init方法:为属性赋值和执行构造方法。
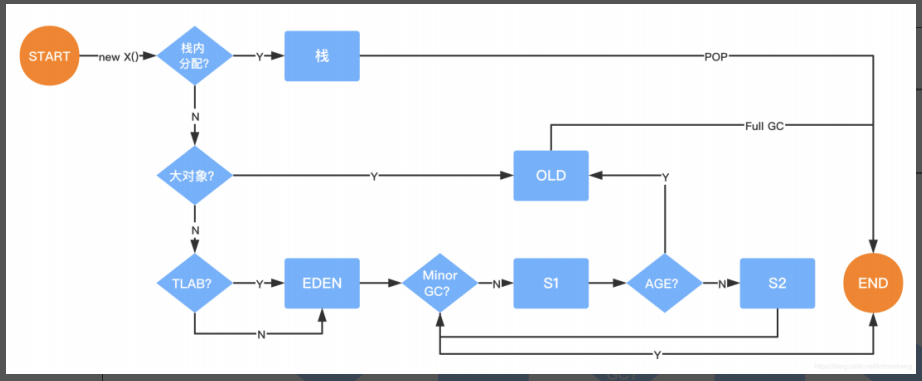
# 对象内存分配
先判断是否需要栈内分配,通过逃逸分析进行判断;
然后判断对象是否属于大对象;
- 若是,直接分配至堆内存的老年代区域;
- 若否,在堆内存的年轻代的Eden区分配内存空间。
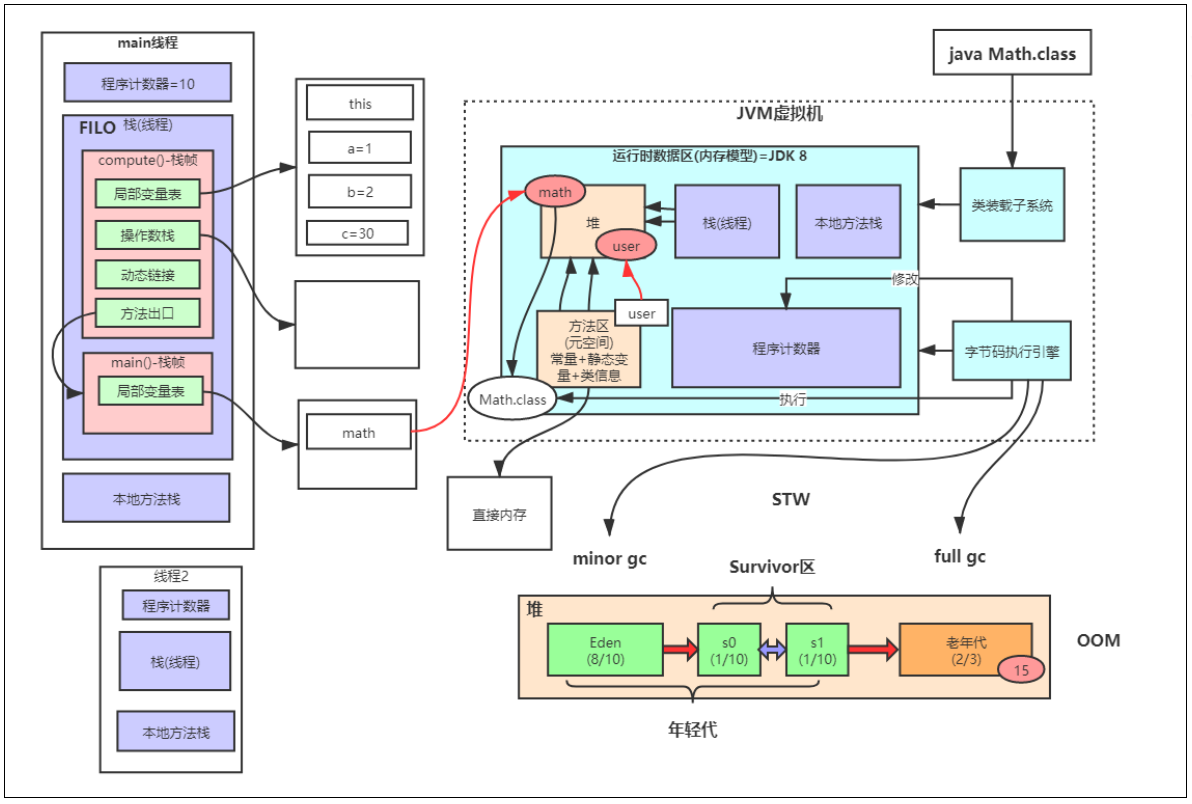
# JVM内存模型
类装载子系统、字节码执行引擎、运行时数据区
运行时数据区分为:
方法区(元空间)、线程栈、本地方法栈、堆、程序计数器;
- 栈:
每一个方法分配一块内存空间——栈帧。
栈帧:
局部变量表、操作数栈、动态链接、方法出口;
- 堆:
年轻代、老年代(1:2)
年轻代:Eden区、Servior区(s0区、s1区)(8:1:1)
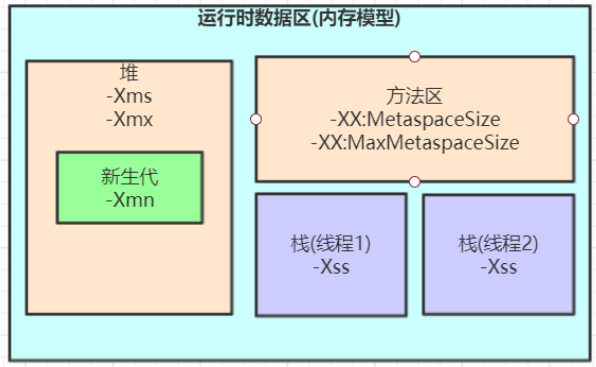
# JVM内存参数设置
- 方法区:
-XX:-XX:MetaspaceSize=N,指定元空间触发Fullgc的初始阈值(元空间无固定初始大小), 以字节为单位,默认是21M。-XX:MaxMetaspaceSize=N,设置元空间最大值, 默认是-1, 即不限制, 或者说只受限于本地内存大小。
- 栈:
-Xss栈的内存大小默认1M。-Xss设置越小count值越小,说明一个线程栈里能分配的栈帧就越少,但是对JVM整体来说能开启的线程数会更多。
- 堆:
-Xms堆的初始内存大小-Xmx最大内存-Xmn年轻代内存
Spring Boot程序的JVM参数设置格式(或者在Tomcat启动直接加在bin目录下catalina.sh文件里):
java ‐Xms2048M ‐Xmx2048M ‐Xmn1024M ‐Xss512K ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐jar xxx-xxx‐server.jar
# 垃圾收集算法
标记-复制算法(年轻代)
标记-清除算法(老年代、CMS)
标记-整理算法(老年代、parNew)
垃圾回收器
- 年轻代:Serial、ParNew、Parallel
- 老年代:Serial Old 、Parallel Old、 CMS
# JVM性能调优
- Jstack命令:查看所有线程信息(堆栈),可分析找出死锁;
- Jstat命令:可以查看GC压力情况
jvisualvm:JDK自带的JAVA性能分析工具。
# 三、Java基础
# JNI
JNI Java Native Interface
JNI,JAVA本地调用。从JAVA1.1开始,JNI标准成为JAVA平台的一部分,它允许JAVA代码和其他语言写的代码进行交互。
JNI弥补了JAVA的与平台无关的这一重大优点的不足,在JAVA实现跨平台的同时,使用JNI,也能与其他语言(如C、C++)的动态库进行交互,给其他语言发挥优势的机会。
使用JNI技术调用本地代码相对比较繁琐,因此又引入了JNA技术。
# JNA
JNA Java Native Access
JNA是建立在JNI技术基础之上的一个JAVA类库。
它使我们可以方便地使用JAVA直接访问动态链接库中的函数。
例如,JNA中提供了一个动态的C语言编写的转发器,可以自动实现JAVA和C的数据类型映射,你不再需要编写C动态链接库。
使用JNA技术比使用JNI技术调用动态链接库会有些微的性能损失,但影响不大。
# 面向对象
万物皆对象,是面向对象编程的核心思想。
对比面向过程来看,面向过程注重于事情的每一个步骤和顺序,比较直接高效;
而面向对象注重于事情有哪些参与者和各自需要做什么,更易于复用扩展和维护。
# 面向对象三大特性
- 封装:封装的意义在于将对象的一些共性属性及行为进行封装,包装到类中。内部细节对外不可见,外部只需调用使用即可,无需关系内部如何实现。
- 继承:即继承就是将具有相同属性和行为的对象,抽象出来并包装成一个父类。
- 多态:即多态就是多种形态,相同的属性和行为,却有不同的表现形式。
# 面向对象七大设计原则
面向对象设计原则,为我们提供了方法和准则。
开口合里最单依
- 开闭原则:面向扩展开发,面向修改关闭。
- 面向接口原则:接口隔离原则
- 组合聚合原则
- 里氏替换原则
- 最少知识原则:迪米特法则
- 单一职责原则:一个类只做一种事,一个方法只做一件事;
- 依赖倒置原则
# 编码
# ASCII
计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此8个二进制位就可以组合出256种状态,这被称为一个字节(byte)。
也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码。比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
# 非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。
于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。
注意:虽然都是用多个字节表示一个符号,但是GB类的汉字编码与 Unicode 和 UTF-8 是毫无关系的。
# Unicode
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。
每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org (opens new window),或者专门的汉字对应表。 (opens new window)
Unicode的问题 需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题;
- 第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道3个字节表示一个符号,而不是分别表示3个符号呢?
- 第二个问题是,我们已经知道,英文字母只用1个字节表示就够了,如果 Unicode 统一规定,每个符号用3个或4个字节表示,那么每个英文字母前都必然有2到3个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
- 出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。
- Unicode 在很长一段时间内无法推广,直到互联网的出现。
# UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0。后面字节的前两位一律设为10,剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。

根据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字“严”为例,演示如何实现 UTF-8 编码。
“严”的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
# 大端序、小端序
Little endian 小端序、小头方式
Big endian 大端序、大头方式
字节序,又称端序或尾序(英语中用单词:Endianness 表示),在计算机领域中,指电脑内存中或在数字通信链路中,占用多个字节的数据的字节排列顺序。
字节的排列方式有两个通用规则:
大端序(Big-Endian)将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。
这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。
小端序(Little-Endian),将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序。
小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。

以汉字"严"为例,Unicode 码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,这就是 Big endian 方式;25在前,4E在后,这是 Little endian 方式。
# 基础数据类型
# 八种基础数据类型
Java的基础数据类型有四类八种。
| 基础数据类型 | 名称 | 占用字节 | 默认值 | 包装类 |
|---|---|---|---|---|
| byte | 字节型 | 1 | 0 | Byte |
| short | 短整型 | 2 | 0 | Short |
| int | 整型 | 4 | 0 | Integer |
| long | 长整型 | 8 | 0L | Long |
| float | 浮点型 | 4 | 0.0f | Float |
| double | 双精度浮点型 | 8 | 0.0d | Double |
| char | 字符型 | 2 | \u0000 | Character |
| boolean | 布尔型 | 1 | false | Boolean |
1、整型
byte 、short 、int 、long
取值范围
| 基础数据类型 | 取值范围 | 取值范围 |
|---|---|---|
| byte | -128 ~ 127 | -2^7 ~ 2^7-1 |
| short | -32768 ~ 32767 | -2^15 ~ 2^15-1 |
| int | -2147483648 ~ 2147483647 | -2^31 ~ 2^31-1 |
| long | -9223372036854774808 ~ 9223372036854774807 | -2^63 ~ 2^63-1 |
2、浮点型
float 、 double
double 类型比float 类型存储范围更大,精度更高。
带小数点的字面量默认属于double类型,所以声明一个float类型的变量时,都要在数字后面加上 "F" 或 "f"。
在Java中,对浮点型数据使用基本的加减乘除运算符,计算的数据可能不是完全精确的,有时候可能出现小数点后几位浮动。对于金融行业或者和钱有关的业务来说,这是不可接受的,当出现与金钱数值相关的场景,建议使用BigDecimal 进行运算。
3、字符型
char
char 有以下的初始化方式:
// 可以是汉字,因为是Unicode编码
char ch = 'a';
// 可以是十进制数、八进制数、十六进制数等等。
char ch = 1010;
// 可以用字符编码来初始化,如:'\0' 表示结束符,它的ascll码是0,这句话的意思和 ch = 0 是一个意思。
char ch = '\0';
2
3
4
5
6
Java是用 unicode 来表示字符。
unicode / gbk / gb2312 是2个字节,utf-8 是3个字节。
例:“中” 这个中文字符在 unicode 就是2个字节,在utf-8就是3个字节。
对于字符串(String),可以通过 String.getBytes(encoding) 方法,获取指定编码类型的byte数组。
4、布尔型
boolean
boolean 型只有两个取值 true 和 false,它的默认值是 false。
对于布尔型占用的空间,得看JVM对于它的具体实现,有些JVM底层其实是使用0和1来表示true和false,那么就是4字节。
# 基本类型之间的转换
在Java中,将一种类型的值赋值给另一种类型是很常见的。
- boolean 类型与其他7种类型的数据都不能进行转换;
- char 类型不支持自动转换成它,只支持强制转换。
除了以上这两种类型有些特殊以外,其他6种数据类型,它们之间都可以进行相互转换,只是可能会存在精度损失。
转换分类
- 自动转换:隐式的,对程序员无感知;
- 强制转换:显式的,需指定目标类型;
将6种数据类型按取值范围的大小顺序排列一下:
double > float > long > int > short > byte
取值范围从小转换到大,是可以直接转换的;
而从大转成小,或转成 char 类型,则必须使用强制转换。
| 数据类型 | 支持自动转换的类型,反之则需要强制转换 |
|---|---|
| byte | |
| short | byte |
| int | char、short、byte |
| long | int、char、short、byte |
| float | long、int、char、short、byte |
| double | float、long、int、char、short、byte |
| char |
# 自动转换
自动转换时会进行扩宽(widening conversion)。
因为较大的类型(如int)要保存较小的类型(如byte),取值范围是足够的,不需要强制转换。
在自动类型转化中,除了以下几种情况可能会导致精度损失以外,其他类型的自动转换不会出现精度损失。
- int--> float
- long--> float
- long--> double
- float --> double
除了可能的精度损失外,自动转换不会出现任何运行时(run-time)异常。
# 强制转换
如果要把大的转成小的,或者在short与char之间进行转换,就必须强制转换。
这也被称作缩小转换(narrowing conversion),因为必须显式地使数值更小以适应目标类型。
强制转换的格式和实例如下:
(target-type) value;
// 实例
long lo = 99;
int i = (int) lo;
2
3
4
5
严格地说,byte转为char不属于缩小转换,因为从byte到char的过程其实是byte-->int-->char,所以widening和narrowing都有。
强制转换可能会损失精度,主要有两种场景:
- 整数类型之间相互转换,如果整数超出目标类型范围,会对目标类型的范围取余数。
- 从浮点类型转成整数类型,会发生截尾(truncation),也就是把小数的部分去掉,只留下整数部分。此时如果整数超出目标类型范围,一样将对目标类型的范围取余数。
# 类型自动提升
在表达式计算过程中会发生类型转换,这些类型转换就是类型提升。
类型提升规则如下:
所有 byte/short/char 的表达式都会被提升为 int。
除以上类型,其他类型在表达式中,都会被提升为取值范围大的那个类型。
例如有一个操作数为double,整个表达式都会被提升为double。
# 包装类
Java为每一个基本类型都提供了相应的包装类,封装了很多实用的方法。
最重要的是,提供了自动装箱和自动拆箱的语法糖,让开发者可以无感知的在包装类型和基础类型之间来回切换。
- boolean --> Boolean
- char --> Character
- byte --> Byte
- short --> Short
- int --> Integer
- long --> Long
- float --> Float
- double --> Double
- char[] --> String(字符串)
# 反射
反射reflect,在运行状态中,对于任意一个类,通过它的对象可以动态地获取类的所有属性和方法。这种动态获取类中信息就称为Java反射。
# 获取Class对象的方式
- Oject类的
getClass方法; - 类名.class获取;
- Class类的
forName("包名.类名")方法;
# 什么时候使用反射
当程序编译时,无法得知该对象属于哪些类时使用反射。
# Java异常体系
Throwable:顶级父类
Error:是系统错误,程序无法处理的错误,一旦出现Error,系统将被迫停止运行。
Exception:程序员能够处理的异常都是Exception,它不会导致程序停止。
RuntimeException:是指发生在程序运行过程中的异常。
CheckedException:是指在程序编译过程中出现的异常。
# UML
UML Unified Model Language 统一建模语言
UML是由一整套图表组成的标准化建模语言。
# 为什么要用UML
通过使用UML使得在软件开发之前, 对整个软件设计有更好的可读性,可理解性,从而降低开发风险。同时,也能方便各个开发人员之间的交流。
UML提供了极富表达能力的建模语言,可以让软件开发过程中的不同人员分别得到自己感兴趣的信息。
# UML的主要目的
- 为用户提供现成的、有表现力的可视化建模语言,以便他们开发和交换有意义的模型。
- 为核心概念提供可扩展性 (Extensibility) 和特殊化 (Specialization) 机制。
- 独立于特定的编程语言和开发过程。
- 为了解建模语言提供一个正式的基础。
- 鼓励面向对象工具市场的发展。
- 支持更高层次的开发概念,如协作,框架,模式和组件。
- 整合最佳的工作方法 (Best Practices)。
# UML分类
1、结构图
包括类图、轮廓图、组件图、组合结构图、对象图、部署图、包图。
2、行为图
包括活动图、用例图、状态机图和交互图。
交互图又分为序列图、时序图、通讯图、交互概览图。


# 四、Java集合
# 五、并发编程
# 并发编程三要素
- 原子性:不可分割的操作,保证要么同时成功,要么同时失败;
- 有序性:程序执行的顺序和代码的顺序保持一致;
- 可用性:一个线程对共享变量的修改,另一个线程可见;
# 线程池
使用ThreadPoolExecutor创建线程池。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//...
}
2
3
4
5
6
7
8
9
# 七大参数
- corePoolSize:核心线程数,线程池正常情况下保持的线程数。
- maximumPoolSize:最大线程数,当线程池繁忙时最多可以拥有的线程数。
- keepAliveTime:空闲线程存活时间,没有活之后“短工”可以生存的最大时间。
- TimeUnit:时间单位。
- BlockingQueue:线程池任务队列,用于保存线程池待执行任务的容器。
- ThreadFactory:创建线程的工厂,用于创建线程池中线程的工厂方法。
- RejectedExecutionHandler:拒绝策略,当任务量超过线程池可以保存的最大任务数时执行的策略。
# 六、算法
# 七、设计模式
# 为什么引入设计模式
项目的业务是在不断变化迭代,引入设计模式的前提,就是在变化的需求中,找到那些稳定的部分。当代码在变化的过程中能够找到稳定的部分,才有引入设计模式的价值。
# 23种设计模式
# 八、网路
# 网络七层架构
OSI参考模型
从下至上分别是:物理层、数据链路层、网际层、传输层、会话层、表示层、应用层
# 网络四层架构
TCP/IP参考模型
从下至上分别是:物理层、网络层、传输层、应用层
# 网络结构
- C/S 客户端/服务端
- B/S 浏览器/服务端
# IP
IP (Internet Protocol) 网络协议
| 分类 | 地址表示 | 示例 |
|---|---|---|
| IPV4 | 32位地址 | 192.168.1.110 |
| IPV6 | 128位地址,8个16进制的无符号正式,之间用冒号分隔 | CDCD:910A:2222:5498:8475:1111:3900:2020 |
# 子网掩码
表示方式:
255.255.255.0(默认),换算为数字为192.168.0.110/24。
标识当前网端可分配254台电脑——192.168.0.[1-254]
换算方法:
IPV4:二进制表示
00000000.00000000.00000000.00000000
从左往右,数字为24,即由24个1表示:
11111111.11111111.11111111.00000000
换算为十进制表示为255.255.255.0
- 192.168.0.110/23,即展示为二进制是255.255.254.0。该网端有可分配254x2台电脑(IP地址)。192.168.0.[1-254]、192.168.1.[1-254]。
- 192.168.0.110/22,即展示为二进制是255.255.252.0。该网端有可分配254x3台电脑(IP地址)。192.168.0.[1-254]、192.168.1.[1-254]、192.168.2.[1-254]。
子网掩码不可设置过大。一般根据当前网络环境所需要多少台电脑,设置合适的子网掩码。因为网络IP由交换机/路由器去搜索定位,那么如果子网掩码设置过大,那么寻址过程会变得很慢,降低网络性能。
# TCP
TCP (Transmission Control Protocol) 传输控制协议
点对点建立连接的可靠协议。
# TCP三次握手
第一次:客户端向服务端发送建立连接的请求,发送SYN = 1 ACK = 0 seq = x 。
SYN = 1表示这是一个连接请求或连接接收报文;ACK = 0表示未确认;seq = x表示客户端自己的初始序号,此时客户端处于等待状态。
第二次:服务器如果监听到客户端请求,如果同意建立连接,则发送SYN = 1 ACK = 1 seq = y ack = x + 1。
再发送
SYN=1请求和客户端建立连接;ACK=1表示确认建立连接;ack = x + 1表示期望收到对方下一个报文段的第一个数据字节序号是x+1;seq = y表示Server 自己的初始序号。此时服务器表示已收到客户端的连接请求,服务器处于等待状态。
第三次:客户端收到确认后还需再次发送确认给服务端,发送ACK = 1 seq = x + 1 ack = y + 1 。
- ACK = 1 表示确认;
- 服务器ack= y + 1 有效;
- 客户端自己的设置为序号seq= x + 1。

# TCP四次挥手
# HTTP
HTTP (Hyper Text Transfer Protocol) 超文本传输协议
HTTP是用于从万维网服务器传输超文件到本地浏览器的传输协议。在OSI模型位于应用层。
通过浏览器访问网页就直接使用了HTTP协议,使用HTTP协议时,客户端首先会与服务的的80端口建立一个TCP连接,然后在这个连接上进行请求和响应。
请求方法常用有GET、POST、PUT、PATCH、DELETE。
HTTP允许传输任意类型的数据对象,由Content-Type加以标记。
HTTP协议是无状态协议,可支持B/S、C/S模式。
请求消息Request包含:请求行、请求头、空行、请求体;
响应消息Response包含:状态行、应答消息头、空行、应答体;
# HTTPS
HTTPS是在TCP层和HTTP层之间加入了SSL/TLS来位上层的安全保驾护航。主要用到对称加密、非对称加密、证书等来实现数据加密传输。
# 访问域名请求流程

第一步:域名解析
把域名解析程可用的IP地址和端口号。
- 搜索浏览器自身DNS缓存,若有且没有过期,则解析结束;若无则搜索系统自身的DNS缓存。
- 查看系统的hosts文件,查看是否配置了域名,若有则解析结束;若无则远程发起DNS域名解析请求。
第二步:发起TCP三次握手
拿到IP地址后,浏览器会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序(常用的nginx)80端口发起TCP的连接请求。
第三步:建立TCP连接后发起http请求
HTTP请求报文由三部分组成:请求行,请求头和请求体。
第四步:服务器端响应http请求,浏览器得到html代码
服务器端WEB程序接收到http请求以后,就开始处理该请求,处理之后就返回给浏览器html文件。
HTTP响应报文也由三部分组成:状态码,响应头和响应体。
第五步:浏览器解析html代码,并请求html代码中的资源
浏览器拿到html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载。
第六步:浏览器对页面进行渲染呈现给用户
最后,浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。
# Socket
Socket,套接字,是为网络服务提供的一种机制、连接方式。它不是一种协议,是网络上运行的两个程序间双向通信的一端。
网络通信其实就是Socket通信。
两端建立连接后,通过Socket中的IO流进行数据的传输。
# 本机hosts文件
从桌面进入“
计算机”,双击打开“C盘”。依次双击打开“
windows”→“System32”→“drivers”→“etc”。在“
etc”文件夹中,用记事本打开“hosts”文件。
# 九、其他
# 延时任务Delayed
实现延时任务的方式:
- JDK的延时队列 DelayQueue。
- RabbitMQ的延迟队列:使用TTL+死信队列来实现。
# Java接口调用方式
| 方式 | 厂商 | 描述 |
|---|---|---|
| URLConnection | ||
| HttpClient | Apache提供 | |
| OKhttp | ||
| RestTemplate | Spring提供 | |
| Feign |
# 负载均衡
# 分类
集中式负责均衡
- 硬件:F5
- 软件:Nginx
客户端负责均衡
- Ribbon
# 负载均衡策略
- 轮询
- 随机
- 重试机制
- 权重
- Hash
# 加密方式
不可逆加密
特点是密钥,常用场景是用户密码加密。有MD5、SHA1、SHA2、SHA-256、SHA-512等。
可逆加密
对称加密
数据加密和解密使用的同一密钥。例:DES、AES。
非对称加密
有两个不同的密钥(公钥、私钥),只有使用相匹配的一对公钥和私钥,才能加密、解密。有RSA、SM2等。
# 长连接、短连接
- 长连接:连接→传输数据→保持连接→ ... →关闭
- 短连接:连接→传输数据→关闭连接
# 十、Java FQA
Java常见问题
# Java概念
# 1、Final
Final , 翻译为最终的,在java中,可用于:
- 修饰类:表示类不可被继承;
- 修饰方法:表示方法不可被子类覆盖(@Override),但可以重载(overload);
- 修饰变量:表示变量一旦被赋值,就不可更改;
# 2、接口和抽象类
| 对比 | 接口 | 抽象类 |
|---|---|---|
| 函数 | 只能存在public abstract,隐式实现 | 可以存在普通成员函数 |
| 成员变量 | 只能是public static final修饰,隐式实现 | 可以是各种类型 |
| 继承、实现 | 一个类可实现多个接口 | 抽象类只能被继承一个 |
- 接口的设计目的,是对类的行为进行约束,也就是提供一种机制,只约束了行为的有无,而不对实现进行限制;
- 抽象类的设计目的,是代码复用。当不同的类有一些相同的行为,那么就可以将这些类派生一个抽象类,达到代码复用的目的。
注意:由于每个类只能继承一个类,可以实现多个接口,那么在设计接口和抽象类的时候,要予以衡量。
使用场景:
- 当你关注一个事务的本质时,用抽象类;
- 当你关注一个操作时,用接口;
# 3、重载和重写
- 重载:是指发生在同一类中,方法名必须相同,方法参数的类型、个数、顺序不同称为重载;与方法的返回值和修饰符无关。在编译时就进行验证。
- 重写:是指发生在子父类之间,子类重写父类方法,方法名、参数必须完全相同;返回值、异常要<=父类;访问修饰符>=父类;
# 4、深拷贝与浅拷贝
两者都是指对象的拷贝。一个对象中存在两种类型的属性——基本数据类型、引用数据类型。
- 浅拷贝:指只会拷贝基本数据类型的值,以及引用数据类型的引用地址;
- 深拷贝:指即会拷贝基本数据类型的值,也会将对象实例进行复制,然后引用新拷贝的对象的引用地址;
# 5、泛型中extends和super的区别
- <? extends T> 表示包括T在内的任何T的子类;
- <? super T> 表示包括T在内的任何T的父类。
# 数据类型
# 1、==和equals比较
==
- 若是基本数据类型,== 对比的是栈中的值:
- 若是引用数据类型,比较的是堆中内存对象的地址引用。
int a = 3; int b = 3;
a == b --> true
2
equals
Object中默认实现也是采用的 ==; 而通常String中会重写equals方法,比较的是两个字符串的内容。
# 2、hashcode和equals
equals:java提供用于对比两个对象是否相等;可以重写equals方法,自定义对比规则,来判断是否相等。
若不进行重写,那么默认会采用Object中的equals(),Object中默认实现采用的是 ==,对比的是对象在栈中的值。
hashcode:作用是用于获取哈希码(散列码),它实际上是返回一个int整数。
在java中,对象是存储在堆中,用hash散列表存储,其中存储的是键值对(key-value),key表示对象在堆中的哪个位置,value表示对象。这个int值,就是该哈希表中的索引位置。
Object中定义了hashCode(),该方法的特点是:能根据哈希码,快速检索出所需要的对象。
同一个对象,多次计算其hashcode具备幂等性。
equals和hashcode的关系:
两个对象相等(equals),那么其hashcode也一定相同;
两个对象有相同的hashcode值,但它们不一定是相等的;
若需要覆写equals方法,则需同时覆写hashcode方法;
为什么需要hashcode?
以“hashset如何检查重复”为例,来说明为什么需要hashcode。
- 当有对象加入hashset时,hashset会先计算该对象的hashcode值,来判断对象加入的位置。
- 当计算的索引位置没有值,则表示该对象没有重复出现;
- 当计算的索引位置已经有值,然后会调用equals()方法来判断两个对象是否相同,若相同,则表示已重复;若不相同,再重写散列到其他的位置。
- 判断是否重复,先根据hashcode进行判断,这个就大大减少了equals的次数,提高了执行速度。
# 3、String、StringBuilder、StringBuffer
共同点:
三者都是final类,不允许被继承的,都用来处理字符串。
不同点:
String是不可变的,如果要修改,会新生成一个字符串对象;
例
String s = “abc”; s = “def”;1
2
“abc”对象并没有被修改,而是重新生成一个”def”对象被s引用。
- 而StringBuilder、StringBuffer是可变的,其每次修改都是对原对象本身进行操作,而不会产生新的对象。
线程安全:
- StringBuilder是线程不安全的,而StringBuffer是线程安全的
- StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但执行速度将受锁的影响降低。
运行速度:StringBuilder > StringBuffer > String
总结:
- 对于不频繁修改的字符串,使用String即可;
- 对于需要频繁修改的字符串,在单线程的情况下建议优先使用 StringBuilder 类;在多线程使用共享遍历时使用StringBuffer。
# 集合
# 1、List和Set的区别
| 对比 | List | Set |
|---|---|---|
| 有序,可重复 | 无序,不可重复 | |
| Null值 | 允许存储多个null元素 | 只允许有1个null元素 |
| 遍历 | 可使用迭代器Iterator遍历元素;也可以实例get(index)获取指定下标的元素 | 只能使用迭代器Iterator遍历元素 |
# 2、ArrayList和LinkedList区别
| 对比 | ArrayList | LinkedList |
|---|---|---|
| 底层实现 | 基于动态数组,需要连续内存存储 | 基于链表,可以存储在分散的内存空间 |
| 使用场景 | 适合查询--下标访问(随机访问); | 适合数据的插入与删除 |
| 不足 | 若不是尾插法,涉及到元素的移动,插入性能慢;但若是尾插法并且指定初始容量也能极大提升插入性能; | 不适合查询;遍历LIST的时候,必须使用迭代器iterator,而不建议使用for循环,因为for循环需要通过下标get(i)获取元素,性能消耗极大。不建议使用indexOf返回元素索引 |
| 扩容机制 | 数组长度是固定的,超出长度存储数据时,需要新建数组,然后将原有数组(old)的数据拷贝至新数组; | |
| 实现了Deque,可以当作一个双端队列来使用 |
# 3、HashMap和HashTable的区别
| 对比 | HashMap | HashTable |
|---|---|---|
| 线程安全性 | 线程不安全 | 线程安全,方法内部加synchronized |
| Null值 | key和value都允许存储null | 不允许 |
| 底层实现 | 数组+链表实现 |