# 一、分布式主键简介
# 概述
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一 ID 做标识。此时一个能够生成全局唯一 ID 的系统是非常必要的。概括下来,那业务系统对 ID 号的要求有哪些呢?
全局唯一性:
不能出现重复的 ID 号,既然是唯一标识,这是最基本的要求。
趋势递增:
在 MySQL InnoDB 引擎中使用的是聚集索引,由于多数 RDBMS 使用 B-tree 的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
单调递增:
保证下一个 ID 一定大于上一个 ID,例如事务版本号、IM 增量消息、排序等特殊需求。
信息安全:
如果 ID 是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定 URL 即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要 ID 无规则、不规则。
注意: 上述前三点对应三类不同的场景,3 和 4 需求还是互斥的,无法使用同一个方案满足。
# 面临挑战
同时除了对 ID 号码自身的要求,业务还对 ID 号生成系统的可用性要求极高,想象一下,如果 ID 生成系统瘫痪,整个美团点评支付、优惠券发券、骑手派单等关键动作都无法执行,这就会带来一场灾难。
由此总结下一个 ID 生成系统应该做到如下几点:
- 平均延迟和 TP999 延迟都要尽可能低;
- 可用性 5 个 9(99.999%);
- 高 QPS。
# 解决方案
# 数据库自动生成
以 MySQL 举例,利用给字段设置 auto_increment_increment 和 auto_increment_offset 来保证主键 ID 自增,每次业务使用下列 SQL 读写 MySQL 得到 ID 号。
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
2
3
4
- 优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有 DBA 专业维护。
- ID 号单调自增,可以实现一些对 ID 有特殊要求的业务。
- 缺点:
- 强依赖 DB,当 DB 异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- ID 发号性能瓶颈限制在单台 MySQL 的读写性能。
# 数据库生成
对于 MySQL 性能问题,可用如下方案解决:在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等。比如有两台机器。设置步长 step 为 2,TicketServer1 的初始值为 1(1,3,5,7,9,11…)、TicketServer2 的初始值为 2(2,4,6,8,10…)。
这是 Flickr 团队在 2010 年撰文介绍的一种主键生成策略。如下所示,为了实现上述方案分别设置两台机器对应的参数,TicketServer1 从 1 开始发号,TicketServer2 从 2 开始发号,两台机器每次发号之后都递增 2。
TicketServer1:
auto-increment-increment = 2
auto-increment-offset = 1
TicketServer2:
auto-increment-increment = 2
auto-increment-offset = 2
2
3
4
5
6
7
假设我们要部署 N 台机器,步长需设置为 N,每台的初始值依次为 0,1,2…N-1 那么整个架构就变成了如下图所示:

这种架构貌似能够满足性能的需求,但有以下几个缺点:
系统水平扩展比较困难。
比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台机器发号是 1,2,3,4,5(步长是 1),这个时候需要扩容机器一台。可以这样做:把第二台机器的初始值设置得比第一台超过很多,比如 14(假设在扩容时间之内第一台不可能发到 14),同时设置步长为 2,那么这台机器下发的号码都是 14 以后的偶数。然后摘掉第一台,把 ID 值保留为奇数,比如 7,然后修改第一台的步长为 2。让它符合我们定义的号段标准,对于这个例子来说就是让第一台以后只能产生奇数。扩容方案看起来复杂吗?貌似还好,现在想象一下如果我们线上有 100 台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
ID 没有了单调递增的特性,只能趋势递增,这个缺点对于一般业务需求不是很重要,可以容忍。
数据库压力还是很大,每次获取 ID 都得读写一次数据库,只能靠堆机器来提高性能。
# UUID
UUID (Universally Unique Identifier) 的标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为 8-4-4-4-12 的 36 个字符,示例:550e8400-e29b-41d4-a716-446655440000。到目前为止业界一共有 5 种方式生成 UUID。
- 优点:
- 性能非常高:本地生成,没有网络消耗。
- 缺点:
- 不易于存储:UUID 太长,16 字节 128 位,通常以 36 长度的字符串表示,很多场景不适用。
- 信息不安全:基于 MAC 地址生成 UUID 的算法可能会造成 MAC 地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- ID 作为主键时在特定的环境会存在一些问题,比如做 DB 主键的场景下,UUID 就非常不适用。
注意:
MySQL 官方有明确的建议主键要尽量越短越好 [4],36 个字符长度的 UUID 不符合要求,对 MySQL 索引不利;
如果作为数据库主键,在 InnoDB 引擎下,UUID 的无序性可能会引起数据位置频繁变动,严重影响性能。
# SNOWFLAKE
雪花算法是由 Twitter 公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。在同一个进程中,它首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。 同时由于 时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。例如 MySQL 的 Innodb 存储引擎的主键。
使用雪花算法生成的主键,二进制表示形式 包含 4 部分,从高位到低位分表为:
1bit 符号位、41bit 时间戳位、10bit 工作进程位以及 12bit 序列号位。
符号位 (1bit)
预留的符号位,恒为零。
时间戳位 (41bit)
41 位的时间戳可以容纳的毫秒数是 2 的 41 次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知
Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L);
结果约等于 69.73 年。ShardingSphere 的雪花算法的时间纪元从 2016 年 11 月 1 日零点开始,可以使用到 2086 年,相信能满足绝大部分系统的要求。
工作进程位 (10bit)
该标志在 Java 进程内是唯一的,如果是分布式应用部署应保证每个工作进程的 id 是不同的。该值默认为 0,可通过属性设置。
序列号位 (12bit)
该序列是用来在同一个毫秒内生成不同的 ID。如果在这个毫秒内生成的数量超过 4096 (2 的 12 次幂),那么生成器会等待到下个毫秒继续生成。
注意:
该算法存在 时钟回拨 问题,服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数。 如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序报错;如果在可容忍的范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间后再继续工作。 最大容忍的时钟回拨毫秒数的默认值为 0,可通过属性设置。
# 二、美团Leaf 分布式主键方案
# 什么是 Leaf
GitHub:官方中文文档 (opens new window)
leaf 美团分布式ID生成服务 (opens new window)
Leaf 是美团开源的分布式 ID 生成系统,最早期需求是各个业务线的订单 ID 生成需求。在美团早期,有的业务直接通过 DB 自增的方式生成 ID,有的业务通过 Redis 缓存来生成 ID,也有的业务直接用 UUID 这种方式来生成 ID。以上的方式各自有各自的问题,因此美团决定实现一套分布式 ID 生成服务来满足需求
目前 Leaf 覆盖了美团点评公司内部金融、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。在4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms(TP=Top Percentile,Top 百分数,是一个统计学里的术语,与平均数、中位数都是一类。
TP50、TP90 和 TP99 等指标常用于系统性能监控场景,指高于 50%、90%、99% 等百分线的情况)。
# Leaf-segment
Leaf-segment 数据库方案,在使用数据库的方案上,做了如下改变:
原方案每次获取 ID 都得读写一次数据库,造成数据库压力大。改为利用 proxy server 批量获取,每次获取一个 segment (step 决定大小) 号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
各个业务不同的发号需求用 biz_tag 字段来区分,每个 biz-tag 的 ID 获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,只需要对 biz_tag 分库分表就行。数据库表设计如下:

重要字段说明:
biz_tag 用来区分业务
max_id 表示该 biz_tag 目前所被分配的 ID 号段的最大值
step 表示每次分配的号段长度
原来获取 ID 每次都需要写数据库,现在只需要把 step 设置得足够大,比如 1000。那么只有当 1000 个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从 1 减小到了 1/step,大致架构如下图所示:

test_tag 在第一台 Leaf 机器上是 1~1000 的号段,当这个号段用完时,会去加载另一个长度为 step=1000 的号段,假设另外两台号段都没有更新,这个时候第一台机器新加载的号段就应该是 3001~4000。同时数据库对应的 biz_tag 这条数据的 max_id 会从 3000 被更新成 4000,更新号段的 SQL 语句如下:
Begin
UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx
SELECT tag, max_id, step FROM table WHERE biz_tag=xxx
Commit
2
3
4
- 优点
- Leaf 服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
- ID 号码是趋势递增的 8byte 的 64 位数字,满足上述数据库存储的主键要求。
- 容灾性高:Leaf 服务内部有号段缓存,即使 DB 宕机,短时间内 Leaf 仍能正常对外提供服务。
- 可以自定义 max_id 的大小,非常方便业务从原有的 ID 方式上迁移过来。
- 缺点
- ID 号码不够随机,能够泄露发号数量的信息,不太安全。
- DB 宕机会造成整个系统不可用。
# Leaf-snowflake
Leaf-snowflake 方案完全沿用 snowflake 方案的 bit 位设计,即是 “1+41+10+12” 的方式组装 ID 号。对于 workerID 的分配,当服务集群数量较小的情况下,完全可以手动配置。
Leaf 服务规模较大,动手配置成本太高。所以使用 Zookeeper 持久顺序节点的特性自动对 snowflake 节点配置 wokerID。
Leaf-snowflake 是按照下面几个步骤启动的:
- 启动 Leaf-snowflake 服务,连接 Zookeeper,在 leaf_forever 父节点下检查自己是否已经注册过(是否有该顺序子节点)
- 如果有注册过直接取回自己的 workerID(zk 顺序节点生成的 int 类型 ID 号),启动服务
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的 workerID 号,启动服务

# 弱依赖 ZooKeeper
除了每次会去 ZK 拿数据以外,也会在本机文件系统上缓存一个 workerID 文件。当 ZooKeeper 出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。这样做到了对三方组件的弱依赖。一定程度上提高了 SLA(Service Level Agreement 服务等级协议,是在一定开销下为保障服务的性能和可用性,网站服务可用性 SLA,9 越多代表全年服务可用时间越长服务更可靠,停机时间越短,反之亦然)
# 解决时钟回拨问题
简单解释时钟回拨: 比如你现在电脑上的时间是 2019 年 12 月 25 日晚上 22 点,你通过系统设置了 NTP 时间同步(还记得安装 Linux 的时候我们做了时间同步嘛),假设你的正常睡眠时间稳定在 8 小时也就是 2019 年 12 月 26 日早上 6 点起床,可起床后你发现电脑上的时间是早上 5 点而不是 6 点,你肯定以为是起早了接着再睡一小时 φ(≧ω≦*)♪ 对吧,其实实际时间应该是 6 点,但时间同步服务器的时间倒退一小时,导致你的电脑也跟着倒退一小时,这种现象叫做 时钟回拨 (比如:2017 年闰秒出现过部分机器回拨)。那么此时聪明的你立马就能想到我了个擦这回拨的一小时里我通过雪花算法得到的分布式 ID 肯定出现重复了,这期间不就他喵的主主冲突了嘛,于是你赶紧下楼打个车去公司默默的修复 BUG 了
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的 ID 号,需要解决时钟回退的问题。
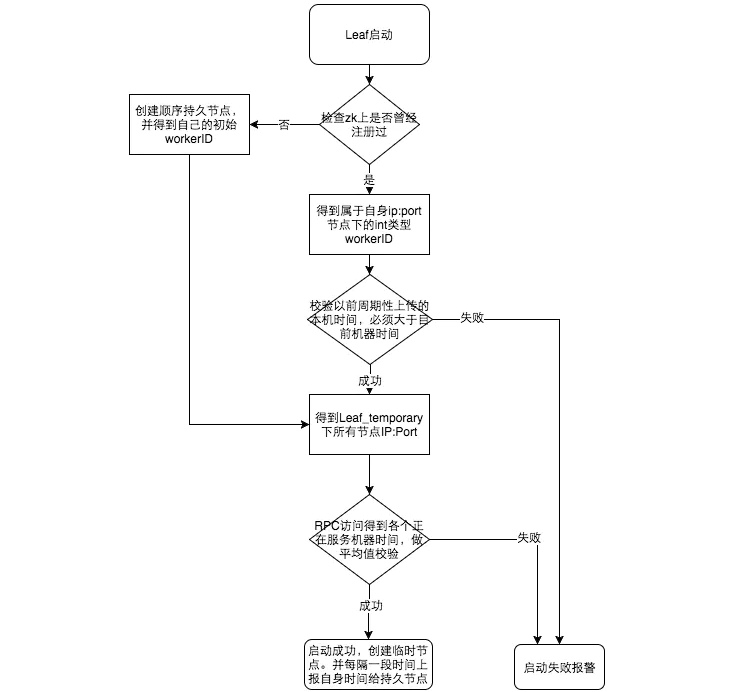
参见上图整个启动流程图,服务启动时首先检查自己是否写过 ZooKeeper leaf_forever 节点:
- 若写过, 则用自身系统时间与 leaf_forever/${self} 节点记录时间做比较,若小于 leaf_forever/${self} 时间则认为机器时间发生了大步长回拨,服务启动失败并报警
- 若未写过, 证明是新服务节点,直接创建持久节点 leaf_forever/${self} 并写入自身系统时间,接下来综合对比其余 Leaf 节点的系统时间来判断自身系统时间是否准确,具体做法是取 leaf_temporary 下的所有临时节点 (所有运行中的 Leaf-snowflake 节点) 的服务 IP:Port,然后通过 RPC 请求得到所有节点的系统时间,计算 sum (time)/nodeSize
- 若 abs (系统时间 - sum (time)/nodeSize ) < 阈值, 认为当前系统时间准确,正常启动服务,同时写临时节点 leaf_temporary/${self} 维持租约,否则认为本机系统时间发生大步长偏移,启动失败并报警。
- 每隔一段时间 (3s) 上报自身系统时间写入 leaf_forever/${self}。
注意: 由于强依赖时钟,对时间的要求比较敏感,在机器工作时 NTP 同步也会造成秒级别的回退,建议可以直接关闭 NTP 同步。要么在时钟回拨的时候直接不提供服务直接返回 ERROR_CODE,等时钟追上即可
# 三、Leaf 使用 Docker 部署
# 概述
我 Fork 了 Leaf 的官方代码在此基础之上制作了 Dockerfile,可以很方便的构建并运行获取雪花算法的 ID
# 克隆
mkdir -p /usr/local/docker/leaf
cd /usr/local/docker/leaf
git clone https://github.com/funtl/Leaf.git
cd Leaf
mvn clean install -DskipTests
2
3
4
5
# 构建
cd leaf-docker
chmod +x build.sh
./build.sh
2
3
# 运行
docker-compose up -d
# 测试
curl http://localhost:8080/api/snowflake/get/test
# 输出如下
1209912709605228625
2
3
4
# 四、Leaf 客户端接入
# 概述
当然,为了追求更高的性能,需要通过 RPC Server 来部署 Leaf 服务,那仅需要引入 leaf-core 的包,把生成 ID 的 API 封装到指定的 RPC 框架中即可。
我们这里先使用 OkHttp3 框架快速接入以便演示完整操作流程
# OkHttp
# 什么是 OkHttp
OKHttp 是一个当前主流的网络请求的开源框架,由 Square 公司开发,用于替代 HttpUrlConnection 和 Apache HttpClient
# OkHttp 特性
- 支持 HTTP2,对一台机器的所有请求共享同一个 Socket
- 内置连接池,支持连接复用,减少延迟
- 支持透明的 gzip 压缩响应体
- 通过缓存避免重复的请求
- 请求失败时自动重试主机的其他 IP,自动重定向
# OkHttp 功能
- PUT,DELETE,POST,GET 等请求
- 文件的上传下载
- 加载图片 (内部会图片大小自动压缩)
- 支持请求回调,直接返回对象、对象集合
- 支持 Session 的保持
# OkHttp 依赖
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.2.2</version>
</dependency>
2
3
4
5
# 封装 OkHttp 工具类
创建一个名为 OkHttpClientUtil 的工具类,代码如下
package com.funtl.spring.cloud.alibaba.commons.net;
import okhttp3.Call;
import okhttp3.Callback;
import okhttp3.MediaType;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.RequestBody;
import okhttp3.Response;
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* OKHttp3
* <p>
* Description:
* </p>
*
* @author Lusifer
* @version v1.0.0
* @date 2019-07-29 14:05:08
* @see com.funtl.spring.cloud.alibaba.commons.net
*/
public class OkHttpClientUtil {
private static final int READ_TIMEOUT = 100;
private static final int CONNECT_TIMEOUT = 60;
private static final int WRITE_TIMEOUT = 60;
private static final MediaType JSON = MediaType.parse("application/json; charset=utf-8");
private static final byte[] LOCKER = new byte[0];
private static OkHttpClientUtil mInstance;
private OkHttpClient okHttpClient;
private OkHttpClientUtil() {
okhttp3.OkHttpClient.Builder clientBuilder = new okhttp3.OkHttpClient.Builder();
// 读取超时
clientBuilder.readTimeout(READ_TIMEOUT, TimeUnit.SECONDS);
// 连接超时
clientBuilder.connectTimeout(CONNECT_TIMEOUT, TimeUnit.SECONDS);
//写入超时
clientBuilder.writeTimeout(WRITE_TIMEOUT, TimeUnit.SECONDS);
okHttpClient = clientBuilder.build();
}
/**
* 单例模式获取 NetUtils
*
* @return {@link OkHttpClientUtil}
*/
public static OkHttpClientUtil getInstance() {
if (mInstance == null) {
synchronized (LOCKER) {
if (mInstance == null) {
mInstance = new OkHttpClientUtil();
}
}
}
return mInstance;
}
/**
* GET,同步方式,获取网络数据
*
* @param url 请求地址
* @return {@link Response}
*/
public Response getData(String url) {
// 构造 Request
Request.Builder builder = new Request.Builder();
Request request = builder.get().url(url).build();
// 将 Request 封装为 Call
Call call = okHttpClient.newCall(request);
// 执行 Call,得到 Response
Response response = null;
try {
response = call.execute();
} catch (IOException e) {
e.printStackTrace();
}
return response;
}
/**
* POST 请求,同步方式,提交数据
*
* @param url 请求地址
* @param bodyParams 请求参数
* @return {@link Response}
*/
public Response postData(String url, Map<String, String> bodyParams) {
// 构造 RequestBody
RequestBody body = setRequestBody(bodyParams);
// 构造 Request
Request.Builder requestBuilder = new Request.Builder();
Request request = requestBuilder.post(body).url(url).build();
// 将 Request 封装为 Call
Call call = okHttpClient.newCall(request);
// 执行 Call,得到 Response
Response response = null;
try {
response = call.execute();
} catch (IOException e) {
e.printStackTrace();
}
return response;
}
/**
* GET 请求,异步方式,获取网络数据
*
* @param url 请求地址
* @param myNetCall 回调函数
*/
public void getDataAsync(String url, final MyNetCall myNetCall) {
// 构造 Request
Request.Builder builder = new Request.Builder();
Request request = builder.get().url(url).build();
// 将 Request 封装为 Call
Call call = okHttpClient.newCall(request);
// 执行 Call
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
myNetCall.failed(call, e);
}
@Override
public void onResponse(Call call, Response response) throws IOException {
myNetCall.success(call, response);
}
});
}
/**
* POST 请求,异步方式,提交数据
*
* @param url 请求地址
* @param bodyParams 请求参数
* @param myNetCall 回调函数
*/
public void postDataAsync(String url, Map<String, String> bodyParams, final MyNetCall myNetCall) {
// 构造 RequestBody
RequestBody body = setRequestBody(bodyParams);
// 构造 Request
buildRequest(url, myNetCall, body);
}
/**
* 同步 POST 请求,使用 JSON 格式作为参数
*
* @param url 请求地址
* @param json JSON 格式参数
* @return 响应结果
* @throws IOException 异常
*/
public String postJson(String url, String json) throws IOException {
RequestBody body = RequestBody.create(JSON, json);
Request request = new Request.Builder()
.url(url)
.post(body)
.build();
Response response = okHttpClient.newCall(request).execute();
if (response.isSuccessful()) {
return response.body().string();
} else {
throw new IOException("Unexpected code " + response);
}
}
/**
* 异步 POST 请求,使用 JSON 格式作为参数
*
* @param url 请求地址
* @param json JSON 格式参数
* @param myNetCall 回调函数
* @throws IOException 异常
*/
public void postJsonAsync(String url, String json, final MyNetCall myNetCall) throws IOException {
RequestBody body = RequestBody.create(JSON, json);
// 构造 Request
buildRequest(url, myNetCall, body);
}
/**
* 构造 POST 请求参数
*
* @param bodyParams 请求参数
* @return {@link RequestBody}
*/
private RequestBody setRequestBody(Map<String, String> bodyParams) {
RequestBody body = null;
okhttp3.FormBody.Builder formEncodingBuilder = new okhttp3.FormBody.Builder();
if (bodyParams != null) {
Iterator<String> iterator = bodyParams.keySet().iterator();
String key = "";
while (iterator.hasNext()) {
key = iterator.next().toString();
formEncodingBuilder.add(key, bodyParams.get(key));
}
}
body = formEncodingBuilder.build();
return body;
}
/**
* 构造 Request 发起异步请求
*
* @param url 请求地址
* @param myNetCall 回调函数
* @param body {@link RequestBody}
*/
private void buildRequest(String url, MyNetCall myNetCall, RequestBody body) {
Request.Builder requestBuilder = new Request.Builder();
Request request = requestBuilder.post(body).url(url).build();
// 将 Request 封装为 Call
Call call = okHttpClient.newCall(request);
// 执行 Call
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
myNetCall.failed(call, e);
}
@Override
public void onResponse(Call call, Response response) throws IOException {
myNetCall.success(call, response);
}
});
}
/**
* 自定义网络回调接口
*/
public interface MyNetCall {
/**
* 请求成功的回调处理
*
* @param call {@link Call}
* @param response {@link Response}
* @throws IOException 异常
*/
void success(Call call, Response response) throws IOException;
/**
* 请求失败的回调处理
*
* @param call {@link Call}
* @param e 异常
*/
void failed(Call call, IOException e);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
# 封装获取 Id 的工具类
创建一个名为 LeafSnowflakeId 的工具类,专门用于获取 leaf-snowflake 生成的 ID
/**
* 通过 Leaf 获取雪花 ID
*/
public class LeafSnowflakeId {
/**
* 注意我这里写死了获取 Leaf 地址,只是为了方便演示
*/
private static final String LEAF_HOST = "http://192.168.106.211:8080/api/snowflake/get/id";
/**
* 生成 ID
*
* @return {@code Long} 雪花 ID
*/
public static Long genId() {
try {
String string = Objects.requireNonNull(OkHttpClientUtil.getInstance().getData(LEAF_HOST).body()).string();
return Long.valueOf(string);
} catch (IOException e) {
return 0L;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 编写测试类
@SpringBootTest
@RunWith(SpringRunner.class)
public class LeafSnowflakeTest {
/**
* 获取leaf雪花算法的ID
* @throws ParseException
*/
@Test
public void testId() throws ParseException {
for (int i = 0; i < 100; i++) {
System.out.println(LeafSnowflakeId.genId());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
五、相关资料
GitHub:官方中文文档 (opens new window)