
# 一、搜索引擎Search Engines
搜索引擎是专门用于搜索数据内容的NoSQL数据库管理系统。除了针对此类应用程序的一般优化外,还包括通常提供以下特点:
- 支持复杂的搜索表达式
- 全文搜索
- 词干分析
- 搜索结果的排序和分组
- 高扩展性的分布式搜索
# 什么是全文检索
全文检索(Full-text Search)是指通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数。
用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户。因为有了具体文本的位置,所以就可以将具体内容读取出来了。
# 常用的全文搜索引擎
- Apache Lucene
- Elasticsearch (opens new window)
- Solr (opens new window)
- Splunk (opens new window)
- Ferret
# 二、Lucene
Lucene全文检索框架,可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库(框架)。
但是想要使用Lucene,必须使用Java来作为开发语言,并将其直接集成到你的应用 中。并且Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它 是如何工作的。
Lucene缺点:
1)耦合度高——只能在Java项目中使用,并且要以jar包的方式直接集成项目中
2)使用非常复杂——创建索引和搜索索引代码繁杂
3)不支持集群环境——索引数据不同步(不支持大型项目)
4)不适合大数据——索引数据如果太多就不行,索引库和应用所在同一个服务器,共同占用硬盘,共用空间少
上述Lucene框架中的缺点,ES全部都能解决。
# 三、Solr
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
ES vs Solr比较
1. 检索速度
当单纯的对已有数据进行搜索时,Solr更快。
当实时建立索引时, Solr会产生IO阻塞,查询性能较差, Elasticsearch具有明显的优势。
大型互联网公司,实际生产环境测试,将搜索引擎从Solr转到 Elasticsearch以后的平均查询速度有了50倍的提升。
总结
二者安装都很简单。
1、Solr 利用 Zookeeper 进行分布式管理;而Elasticsearch 自身带有分布式协调管理功能。
2、Solr 支持更多格式的数据,比如JSON、XML、CSV;而 Elasticsearch 仅支持 json文件格式。
3、Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
4、Solr 是传统搜索应用的有力解决方案;但 Elasticsearch更适用于新兴的实时搜索应用。
# 四、Elasticsearch
slogan
我们帮助人们驾驭搜索的力量,从而以与众不同的方式查看和分析数据。
官方网站: https://www.elastic.co/ (opens new window)
下载地址:https://www.elastic.co/cn/start (opens new window)
# 简介
Elasticsearch是一个基于Lucene的搜索服务器,用Java语言开发。它提供了一个分布式多用户能力的全文搜索引擎(Search Engines),基于RESTful web接口。
Elasticsearch是一个基于JSON的分布式搜索和分析引擎。
官方客户端在Java、.NET(C#)、PHP、Python、Ruby和许多其他语言中都是可用的。
ES默认启用2个HTTP端口 9200和9300:
- 9200端口是对外提供服务的API使用;
- 9300端口是内部通信端口,包括心跳、集群内部信息同步等。
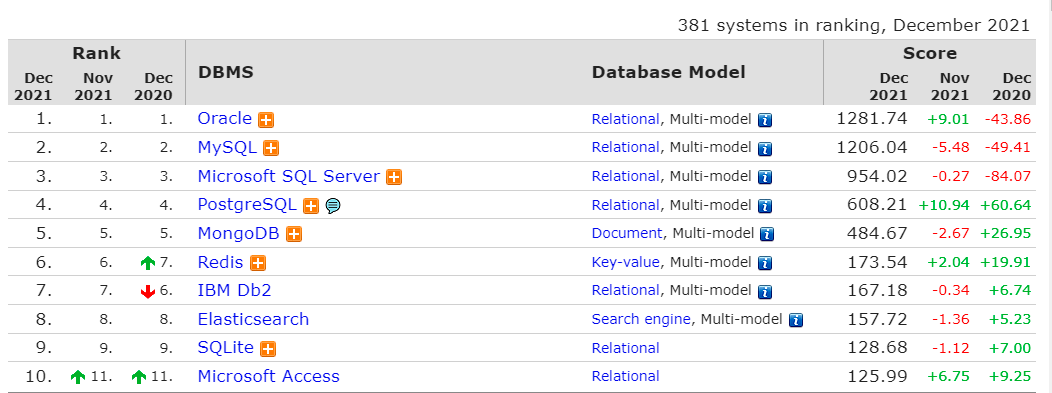
根据DB-Engines (opens new window)的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr(也是基于Lucene)。
# 特点
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。
Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
可扩展性
ElasticSearch支持分布式数据存储和分析查询功能,充分利用Elasticsearch的水平伸缩性,可以轻松扩展到上百台服务器,同时支持处理PB级的结构化或非结构化数据。
搜索速度
Elasticsearch 很快,快到不可思议,其底层使用了强大的设计。我们通过有限状态转换器实现了用于全文检索的倒排索引,实现了用于存储数值数据和地理位置数据的 BKD 树,以及用于分析的列存储。
相关度
基于各项元素(从词频或新近度到热门度等)对搜索结果进行排序。将这些内容与功能进行混搭,以优化向用户显示结果的方式。
# 应用场景
elastic客户
京东 、携程 、去哪儿 、58同城 、滴滴 、今日头条 、小米 、哔哩哔哩 、微软 、Facebook、...

# 实现原理
- 首先用户将数据提交到Elasticsearch 数据库中;
- 再通过
分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据; - 当用户搜索数据时候,再根据
权重将结果排名,打分; - 最后将返回结果呈现给用户。
# 核心名词
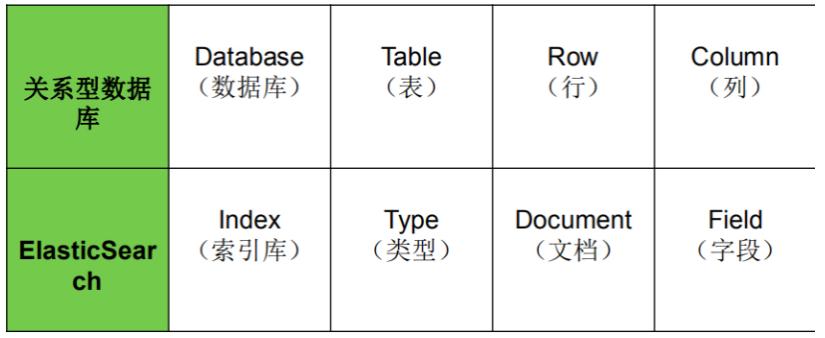
# ES vs 关系型数据库
# 索引库 Index
一个索引相当于传统数据库的database,就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
# 字段类型 Type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等。相当于传统数据库的table。
# 映射 Mapping
ElasticSearch中的映射(Mapping)用来定义一个文档。
Mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的。
# 文档 Document
一个文档是一个可被索引的基础信息单元,类似一条记录/行Row。
文档以JSON(Javascript Object Notation)格式来表示。
# 字段Field
相当于是数据表的列Column。
# 集群 Cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。
每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。
# 节点Node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。
默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中 。这意味着,如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
# 分片Shard
一个索引可以存储超出单个节点硬件限制的大量数据。比如一个具有10亿文档的索引占据1TB的磁盘空间。
但是实际上任一节点都没有这样大的磁盘空间。并且单个节点处理搜索请求,响应太慢。
为了解决上述问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。
当创建一个索引的时候,可以指定你想要的分片的数量。**一旦创建了索引,就不能更改主分片的数量。**每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
至于一个分片怎样分布,它的文档怎样聚合去搜索请求,是完全由 Elasticsearch管理的,对于作为用户来说,这些都是透明的。
分片很重要,主要有两方面的原因:
允许水平分割/扩展你的内容容量(扩容);
允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量(高并发)。
# 副本Replicas
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。
为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本。
副本之所以重要,有两个主要原因:
在分片/节点失败的情况下,提供了高可用性。 复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。(分开存储)
扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
Elasticsearch是分布式的,这意味着每个索引可以被分成多个分片,每个分片可以有0个或者多个副本。
一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引创建的时候指定。
在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变主分片的数量。
# 倒排索引(Inverted Index)
正排索引是由记录来确定属性值;而倒排索引是由属性值来确定记录的位置。
Elasticsearch能够实现快速、高效的搜索功能,正是基于倒排索引原理。
# 幂等性
PUT和DELETE操作是幂等的。
所谓幂等是指不管进行多少次操作,结果都一样。比如用PUT修改一篇文章,然后在做同样的操作,每次操作后的结果并没有什么不同,DELETE也是一样。
# 五、Elastic Stack
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elastic Stack的核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
elastic解决方案
Elastic 为全球范围内数以千计的公司(从初创企业到全球 2000 强企业)打造搜索解决方案,帮助他们搜索文档、监测基础设施、保护企业免受安全威胁,不一而足。
- Elastic 企业搜索
- Elastic 可观测性
- Elastic 安全

# 六、ES安装
# ES服务端安装(Linux)
创建普通用户es
ES不能使用root用户来启动,必须使用普通用户来安装启动。
创建一个普通用户,一个es专门的用户。
定义一些常规目录用于存放我们的数据文件以及安装包等。
使用root用户在服务器执行以下命令:
先创建组, 再创建用户
# 创建 elasticsearch 用户组
groupadd elasticsearch
# 创建用户
sudo useradd -r -m -s /bin/bash es
-r:建立系统账号
-m:自动建立用户的登入目录
-s:指定用户登入后所使用的shell
# 设置密码
sudo passwd es
# 用户es 添加到 elasticsearch 用户组
usermod -G elasticsearch es
输入ls /home/,可以看到用户目录被成功创建了:
ls /home/
2
3
4
5
6
7
8
9
10
11
12
13
14
修改用户权限 把新建的账号增加到管理员组。这里采用修改Ubuntu 18.04系统/etc/sudoers文件的方法分配用户权限。因为此文件只有r权限,在改动前需要增加w权限,改动后,再去掉w权限。
chmod +w /etc/sudoers
vim /etc/sudoers
# 添加下图的配置语句,并且保存修改
es ALL=(ALL:ALL) ALL
yy 把光标移动到要复制的行上,复制当前行;
然后把光标移动到要复制的位置,按p 粘贴。
:wq
再去掉该文件的权限
chmod -w /etc/sudoers
至此,新用户创建成功,并且用户目录被创建,权限也分配成功。
2
3
4
5
6
7
8
9
10
11
上传安装包
# 创建es文件夹
mkdir -p /usr/local/es
chown -R es /usr/local/es/
2
3
将es的安装包下载并上传到服务器的/user/local/es路径下,然后进行解压。
使用es用户来执行以下操作:
# 切换用户
su - es
# 上传安装包后,解压至/usr/local/es目录下
cd /usr/local/es
tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz
# 创建目录
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/data
2
3
4
5
6
7
8
9
修改配置文件
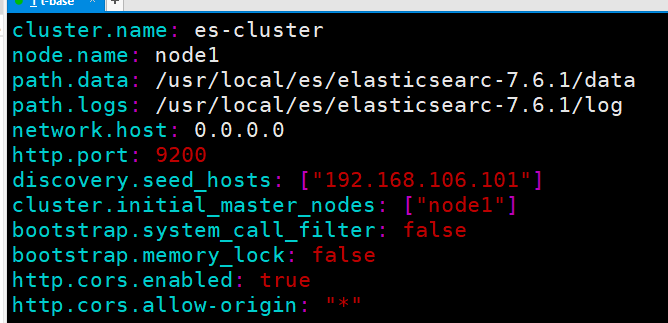
1.修改核心配置文件elasticsearch.yml
cd /usr/local/es/elasticsearch-7.6.1/config
vi elasticsearch.yml
2
cluster.name: es-cluster
node.name: node1
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.106.101"]
cluster.initial_master_nodes: ["node1"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow‐origin: "*"
2
3
4
5
6
7
8
9
10
11
12
2.修改jvm.option 修改jvm.option配置文件,调整jvm堆内存大小 ,将-Xms1g改为-Xms2g
vi jvm.options
3.启动
cd /usr/local/es/elasticsearch-7.6.1/bin/
nohup /usr/local/es/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
tail -f nohup.out
2
3
验证是否成功启动
http://192.168.106.101:9200/?pretty
# 客户端Kibana安装(5601)
Kibana:ES主流图形界面客户端。
Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
Kibana 核心产品搭载了一批经典功能:柱状图、线状图、饼图、旭日图等等。当然,您还可以搜索自己的所有文档。
安装步骤:
1)下载Kibana放之/usr/local/es目录中 2)解压文件:tar -zxvf kibana-X.X.X-linux-x86_64.tar.gz 3)进入/usr/local/es/kibana-X.X.X-linux-x86_64/config目录
tar -zxvf kibana-7.6.1-linux-x86_64.tar.gz
cd /usr/local/es/kibana-7.6.1-linux-x86_64/config
vi kibana.yml
2
3
打开注释,修改如下三处内容
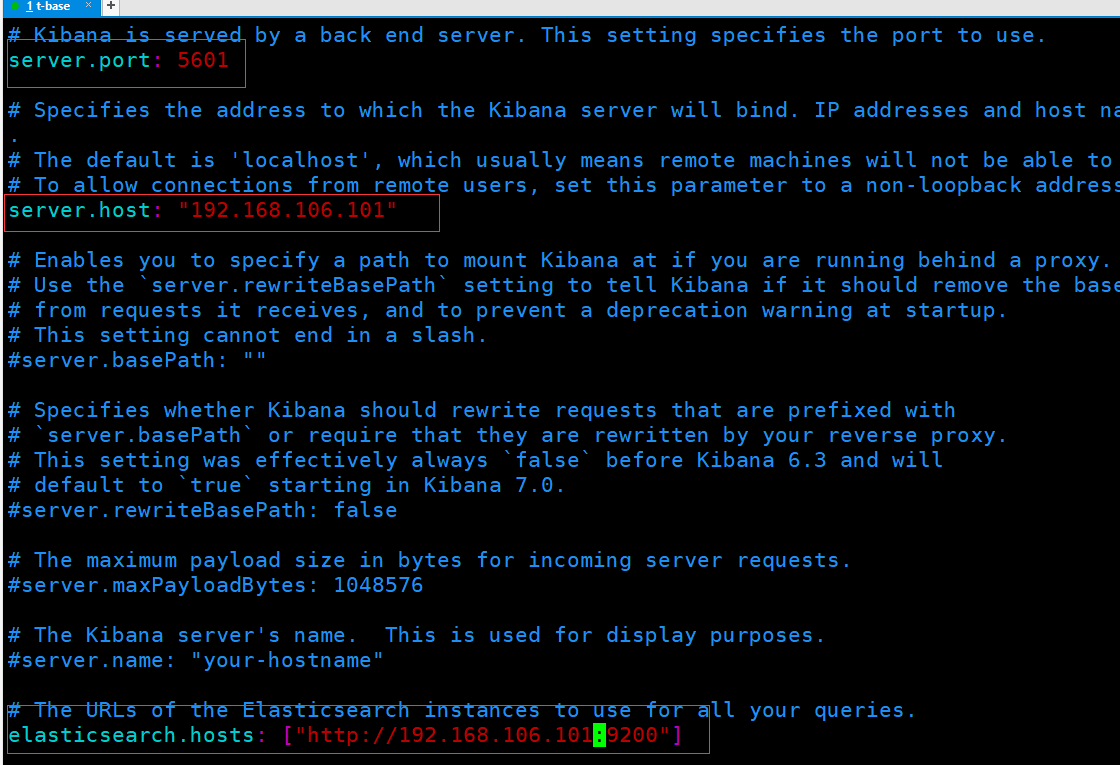
启动
nohup /usr/local/es/kibana-7.6.1-linux-x86_64/bin/kibana &
访问 http://192.168.106.101:5601/app/kibana
# IK分词器安装
我们后续也需要使用Elasticsearch来进行中文分词,所以需要单独给Elasticsearch 安装IK分词器插件。
以下为具体安装步骤:
- 下载Elasticsearch IK分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases
- 切换到es用户,并在es的安装目录下/plugins创建ik
sudo mkdir -p /usr/local/es/elasticsearch-7.6.1/plugins/ik
- 将下载的ik分词器上传并解压到该目
cd /usr/local/es/elasticsearch-7.6.1/plugins/ik
sudo unzip elasticsearch-analysis-ik-7.6.1.zip
2
3
- 重启Elasticsearch
kill 进程ID
cd /usr/local/es/elasticsearch-7.6.1/bin/
nohup /usr/local/es/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
tail -f nohup.out
2
3
4
5
# 七、ES使用
# ES数据管理
ES是面向文档(document oriented)的,这意味着它可以存储整个对象或文档 (document)。
然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。
在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES使用JSON作为文档序列化格式。( JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式)
ES存储的一个员工文档的格式示例:
{
"email": "584614151@qq.com",
"name": "张三",
"age": 30,
"interests": [
"篮球",
"健身"
]
}
2
3
4
5
6
7
8
9
ES的主键字段为_id。
HTTP方法
| HTTP方法 | 说明 |
|---|---|
| GET | 获取请求对象的当前状态 |
| POST | 改变对象的当前状态 |
| PUT | 创建一个对象 |
| DELETE | 销毁对象 |
| HEAD | 请求获取对象的基础信息 |
# 基本操作索引库
- 创建索引
格式: PUT /索引名称
举例: PUT /es_db
- 查询索引
格式: GET /索引名称
举例: GET /es_db
- 删除索引
格式: DELETE /索引名称
举例: DELETE /es_db
# 基本操作文档
- 添加文档
格式: PUT /索引名称/类型/id
PUT /es_db/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
2
3
4
5
6
7
8
添加操作可以使用PUT,也可以使用POST。
POST /es_db/_doc
{
"_id": 2,
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
2
3
4
5
6
7
8
9
PUT与POST的区别(添加):
- PUT操作是作用在一个具体资源之上的(/_doc/1);
- 而POST是作用在一个集合资源(/_doc)之上的。
- 修改文档
格式: PUT /索引名称/类型/id
PUT /es_db/_doc/1
{
"name": "张三22222",
"sex": 1,
"age": 25,
"address": "广州天河公园2222",
"remark": "java developer"
}
2
3
4
5
6
7
8
格式: POST /索引名称/类型/id
POST /es_db/_doc/1
{
"name": "张三22222",
"sex": 1,
"age": 25,
"address": "广州天河公园2222",
"remark": "java developer"
}
2
3
4
5
6
7
8
PUT与POST的区别(修改):
- PUT会将新的json值完全替换掉旧的;
- 而POST方式只会更新相同字段的值,其他数据不会改变,新提交的字段若不存在则增加。
- 查询文档
格式: GET /索引名称/类型/id
举例: GET /es_db/_doc/1
- 删除文档
格式: DELETE /索引名称/类型/id
举例: DELETE /es_db/_doc/1
# 文档条件查询
- 查询当前类型中的所有文档
格式: GET /索引名称/类型/_search
- 等值查询
格式: GET /索引名称/类型/_search?q=:**
- 范围查询
格式: GET /索引名称/类型/_search?q=***[25 TO 26]
- 不等值查询
格式: GET /索引名称/类型/_search?q=age:<=**
- 批量查询
格式: GET /索引名称/类型/_mget
- 分页查询
格式: GET /索引名称/类型/_search?q=age[25 TO 26]&from=0&size=1
- 指定输出项
格式: GET /索引名称/类型/_search?_source=字段,字段
- 排序
格式: GET /索引名称/类型/_search?sort=字段 desc
# 文档批量操作
- 批量获取文档数据
批量获取文档数据是通过_mget的API来实现的 。
(1) 在URL中不指定index和type
请求方式:GET
请求地址:
_mget1功能说明 : 可以通过ID批量获取不同index和type的数据
请求参数 docs : 文档数组参数
_index : 指定index
_type : 指定type
_id : 指定id
_source : 指定要查询的字段
(2) 在URL中指定index
请求方式:GET
请求地址:
/{{indexName}}/_mget1功能说明 : 可以通过ID批量获取不同index和type的数据
请求参数 docs : 文档数组参数
_index : 指定index
_type : 指定type
_id : 指定id
_source : 指定要查询的字段
(3) 在URL中指定index和type
请求方式:GET
请求地址:
/{{indexName}}/{{typeName}}/_mget1功能说明 : 可以通过ID批量获取不同index和type的数据
请求参数 docs : 文档数组参数
_index : 指定index
_type : 指定type
_id : 指定id
_source : 指定要查询的字段
- 批量操作文档数据
批量对文档进行写操作是通过_bulk的API来实现的
请求方式:POST
请求地址:_bulk
请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
第一行参数为指定操作的类型及操作的对象 (例如:index,type和id)
第二行参数才是操作的数据
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}
2
actionName:表示操作类型,主要有create、delete、update 、index
(1) 批量创建文档create
POST _bulk
{"create":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"白起老师1","content":"白起老师666","tags":["java", "面向对 象"],"create_time":1554015482530}
{"create":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"白起老师2","content":"白起老师NB","tags":["java", "面向对 象"],"create_time":1554015482530}
2
3
4
5
(2) 批量删除delete
POST _bulk
{"delete":{"_index":"article", "_type":"_doc", "_id":3}}
{"delete":{"_index":"article", "_type":"_doc", "_id":4}}
2
3
(3) 批量修改delete
POST _bulk
{"update":{"_index":"article", "_type":"_doc", "_id":3}}
{"doc":{"title":"ES大法必修内功"}}
{"update":{"_index":"article", "_type":"_doc", "_id":4}}
{"doc":{"create_time":1554018421008}}
2
3
4
5
# 八、DSL语言高级查询
Domain Specific Language 领域专用语言
Elasticsearch provides a full Query DSL based on JSON to define queries
Elasticsearch提供了基于JSON的DSL来定义查询。
DSL由叶子查询子句和复合查询子句两种子句组成。

# 记录查询Query
# 无查询条件
无查询条件是查询所有,默认是查询所有的,或者使用match_all表示所有 。
GET /user/_doc/_search
{
"query":{
"match_all":{}
}
}
2
3
4
5
6
# 叶子条件查询(单字段查询条件)
- 模糊匹配
模糊匹配主要是针对文本类型的字段。
文本类型的字段会对内容进行分词。查询时,也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据。
模糊匹配主要通过match、prefix 、regexp 等参数来实现 。
- match : 通过match关键词模糊匹配条件内容
- prefix : 前缀匹配regexp : 通过正则表达式来匹配数据
- regexp : 通过正则表达式来匹配数据
match的复杂用法
match条件还支持以下参数:
query : 指定匹配的值
operator : 匹配条件类型
- and : 条件分词后都要匹配
- or : 条件分词后有一个匹配即可(默认)
minmum_should_match : 指定最小匹配的数量。
- 精准匹配
- term : 单个条件相等
- terms : 单个字段属于某个值数组内的值
- range : 字段属于某个范围内的值
- exists : 某个字段的值是否存在
- ids : 通过ID批量查询
# 组合查询(多条件)
组合条件查询是将叶子条件查询语句进行组合而形成的一个完整的查询条件。
bool : 各条件之间有and,or或not的关系
- must : 各个条件都必须满足,即各条件是and的关系
- should : 各个条件有一个满足即可,即各条件是or的关系
- must_not : 不满足所有条件,即各条件是not的关系
- filter : 不计算相关度评分,它不计算_score即相关度评分,效率更高
constant_score : 不计算相关度评分
must/filter/shoud/must_not 等的子条件是通过 term/terms/range/ids/exists/match 等叶子条件为参数的
注:以上参数,当只有一个搜索条件时,must等对应的是一个对象,当是多个条件时,对应的是一个数组。
# 连接查询
父子文档查询:parent/child
嵌套文档查询: nested
# 结果聚合aggs
# 九、IK分词器
**指定IK分词器作为默认分词器 **
ES的默认分词设置是standard,这个在中文分词时就比较尴尬了,会单字拆分。
比如我搜索关键词“清华大学”,这时候会按“清”,“华”,“大”,“学”去分词,然后搜出来的都是些“清清的河水”,“中华儿女”,“地大物博”,“学而不思则罔”之类的莫名其妙的结果。这里我们就想把这个分词方式修改一下。
ik分词器,有两种ik_smart和ik_max_word。
ik_smart会将“清华大学”整个分为一个词;
ik_max_word会将“清华大学”分 为“清华大学”,“清华”和“大学”,按需选其中之一就可以了。
修改默认分词方法(这里修改school_index索引的默认分词为**ik_max_word**):
PUT /school_index {
"settings": {
"analysis.analyzer.default.type": "ik_max_word"
}
}
2
3
4
5