# 一、时序数据库
TSDB(time series database)时序数据库
时序数据库是用来存储时序列数据,以时间建立索引。
从定义上来说,就是一串按时间维度索引的数据。
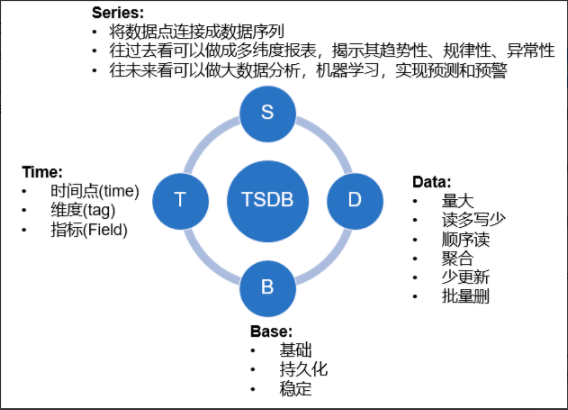
# 特点
- 持续高并发写入、无更新;
- 数据压缩存储;
- 低查询延时。
# 时序数据库的特性
# a. 三大特性
- Time Series (时间序列):你可以使用与时间有关的相关函数(如最大,最小,求和等)
- Metrics(度量):你可以实时对大量数据进行计算
- Eevents(事件):它支持任意的事件数据
# b. 时序特性
- 时间戳
- 采样频率
# c. 数据特性
- 数据顺序追加
- 数据可多维关联
- 高频访问热数据
- 冷数据需要降维归档
- 数据主要覆盖数值,状态,事件
# d. 数据库特性
- 写入速率稳定且远远大于读取
- 按照时间窗口访问数据
- 极少更新,存在一定窗口期的覆盖写
- 批量删除
- 具备通用数据库的高可用,高可靠,可伸缩特性
- 通常不具备事务的能力
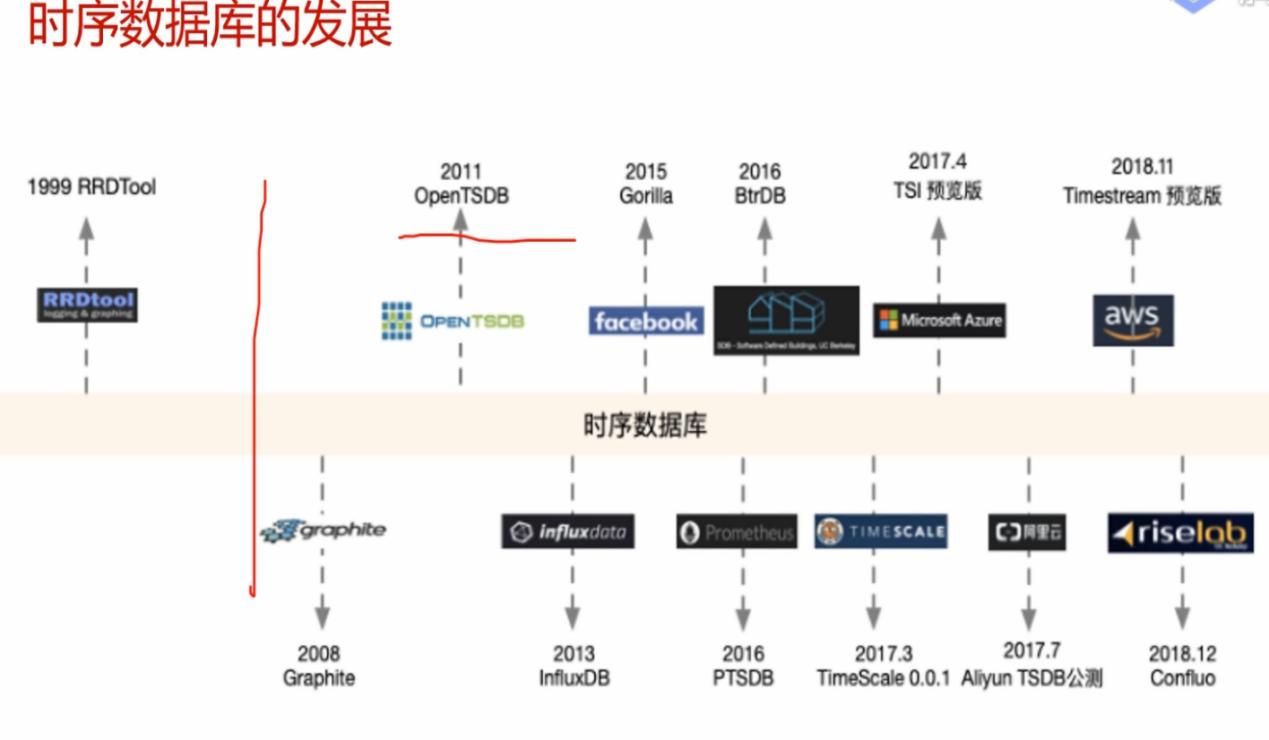
# 时序数据库的发展
时序数据库最初诞生的目的,很大程度上是对标MongoDB。
常见 TSDB:Influxdb、opentsdb、timeScaladb、Druid 等。

# 时间序列模型
时间序列数据库主要用于指处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。
每个时序点结构如下:
timestamp: 数据点的时间,表示数据发生的时间。
metric: 指标名,当前数据的标识,有些系统中也称为name。
value: 值,数据的数值,一般为double类型,如cpu使用率,访问量等数值,有些系统一个数据点只能有一个value,多个value就是多条时间序列。有些系统可以有多个value值,用不同的key表示。
tag: 附属属性。
# 二、InfluxDB基础
InfluxDB GitHub地址 (opens new window)
InfluxDB是专注于时序数据场景的高性能时序型数据库,特别是在IOT(物联网)和监控领域十分常见。
其使用go语言开发,突出特点是性能。
# InfluxDB特性
- 高效的时间序列数据写入性能。自定义TSM引擎,快速数据写入和高效数据压缩。
- 无额外存储依赖。
- 简单,高性能的HTTP查询和写入API。
- 以插件方式支持许多不同协议的数据摄入,如:graphite、collectd、openTSDB。
- SQL-like查询语言,简化查询和聚合操作。
- 索引Tags,支持快速有效的查询时间序列。
- 保留策略有效去除过期数据。
- 连续查询自动计算聚合数据,使频繁查询更有效。
# 应用场景
InfluxDB是专注于时序数据场景,广泛应用于DevOps监控、IoT监控、实时分析等场景。
例如:应用于机房运维监控、物联网IoT设备采集存储、互联网广告点击分析等基于时间线且多源数据连续涌入数据平台的应用场景。
# 优势
InfluxDB专注于DevOps监控、IoT监控等场景,针对时序存储、高性能读写、实时操作、高可用性而设计的一套软件,从零设计架构和开发,InfluxDB通过实现高度可扩展的数据接收和存储引擎,可以高效地实时收集、存储、查询、可视化显示和执行预定义操作。
它通过采样和数据保留策略,以支持将高价值、高精度数据保存在内存中,将低价值数据保存到磁盘。
作为一套精心设计、架构卓越的专用系统,相比OpenTSDB、MongoDB、Graphite、Cassandra等,InfluxDB的性能优势和成本优势明显。
# Influxdb部署
单机版和集群版。
单机版开源;集群版已闭源,走商业路线。
# 数据格式
在 InfluxDB 中,我们可以粗略的将要存入的一条数据看作一个虚拟的 key 和其对应的 value(field value)。
格式如下:
cpu_usage,host=server01,region=us-west value=0.64 1434055562000000000
虚拟的 key 包括以下几个部分:
database, retention policy, measurement, tag sets, field name, timestamp。
- database: 数据库名,在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录。
- retention policy: 存储策略,用于设置数据保留的时间。
- measurement: 测量指标名,对应传统数据库中的表。例如 cpu_usage 表示 cpu 的使用率。
- tag sets: tag sets 在 InfluxDB 中会按照字典序排序,不管是 tagk 还是 tagv,只要不一致就分别属于两个 key,例如 host=server01,region=us-west 和 host=server02,region=us-west 就是两个不同的 tag sets。
- tag--标签,在InfluxDB中,tag是一个非常重要的部分,表名+tag一起作为数据库的索引。是“key-value”的形式。
- field name: 例如上面数据中的 value 就是 fieldName,InfluxDB 中支持一条数据中插入多个 fieldName,这其实是一个语法上的优化,在实际的底层存储中,是当作多条数据来存储。
- timestamp: 每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,为了优化后续的查询操作。也可以传入指定时间。
# 三、InfluxDB名词
| influxDB中的名词 | 传统数据库中的概念 |
|---|---|
database | 数据库 |
measurement | 数据库中的表 |
point | 表里面的一行数据 |

# database
数据库名,在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录。
# measurement
测量指标名,对应传统数据库中的表。
# Timestamp
既然是时间序列数据库,influxdb的数据都有一列名为_time的列,里面存储UTC时间戳。
时间戳的精度可以达到纳秒级(NS),即19位Long类型。
以RFC3339格式显示(2020-01-01T00:00:00.00Z)。
每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,为了优化后续的查询操作。也可以传入指定时间。
# retention policy
RC retention policy 存储策略
存储策略,用于设置数据保留的时间。
每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久。一个库中只允许一个默认策略。
插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。用户可以自己设置,例如保留最近2小时的数据。
InfluxDB 会定期清除过期的数据。
InfluxDB 每秒可以处理成千上万条数据,要将这些数据全部保存下来会占用大量的存储空间,有时我们可能并不需要将所有历史数据进行存储。InfluxDB 没有提供直接删除 Points 的方法,但是它提供了 Retention Policies,用来让我们自定义数据的保留时间。
# Point
表示每个表里某个时刻的某个条件下的一个 field 的数据,因为体现在图表上就是一个点,于是将其称为 point。
Point由时间戳(time)、数据(field)、标签(tags)组成。
Point相当于传统数据库里的一行数据,如下表所示:
| Point属性 | 传统数据库中的概念 |
|---|---|
| time | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| fields | 各种记录值(没有索引的属性) |
| tags | 各种有索引的属性 |
Time 每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,为了优化后续的查询操作。也可以传入指定时间。
field 字段字段由field key和field value组成。field是没有索引的。如果使用这些字段作为查询条件,会扫描符合查询条件的所有字段值。
field key为string类型;field value可以是string,float,integer或boolean类型。
tags标签由tag key和tag value组成。tag是有索引的。tags相当于SQL中的有索引的列,将经常查询的列设定为tag标签。
tag key为string类型;tag value只能是string类型 。
# Series
series 表示这个表里面的数据,即表示可以在图表上画成几条线。 Series 相当于是 InfluxDB 中一些数据的集合。
series 主要通过 tags 排列组合算出来。即在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series。
同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
# Shard
Shard(分片) 在 InfluxDB 中是一个比较重要的概念,它和retention policy相关联。
每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复。
例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。
每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
# TSM 存储引擎
TSM 存储引擎主要由几个部分组成: cache、wal、tsm file、compactor。
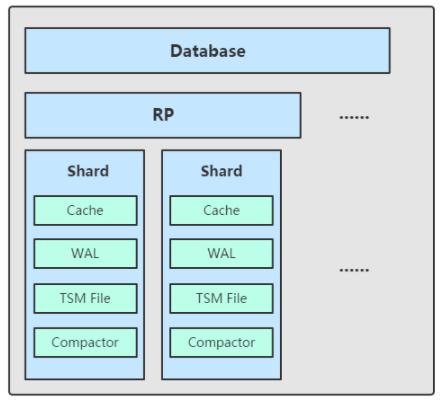
1)Cache:cache 相当于是 LSM Tree 中的 memtabl。插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。
cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB,每当 cache 中的数据达到阀值后,会将当前的 cache 进行一次快照,之后清空当前 cache 中的内容,再创建一个新的 wal 文件用于写入,剩下的 wal 文件最后会被删除,快照中的数据会经过排序写入一个新的 tsm 文件中。
2)WAL:wal 文件的内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据。
3)TSM File:单个 tsm file 大小最大为 2GB,用于存放数据。
4)Compactor:compactor 组件在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据。
主要进行两种操作,一种是 cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中。
另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成。
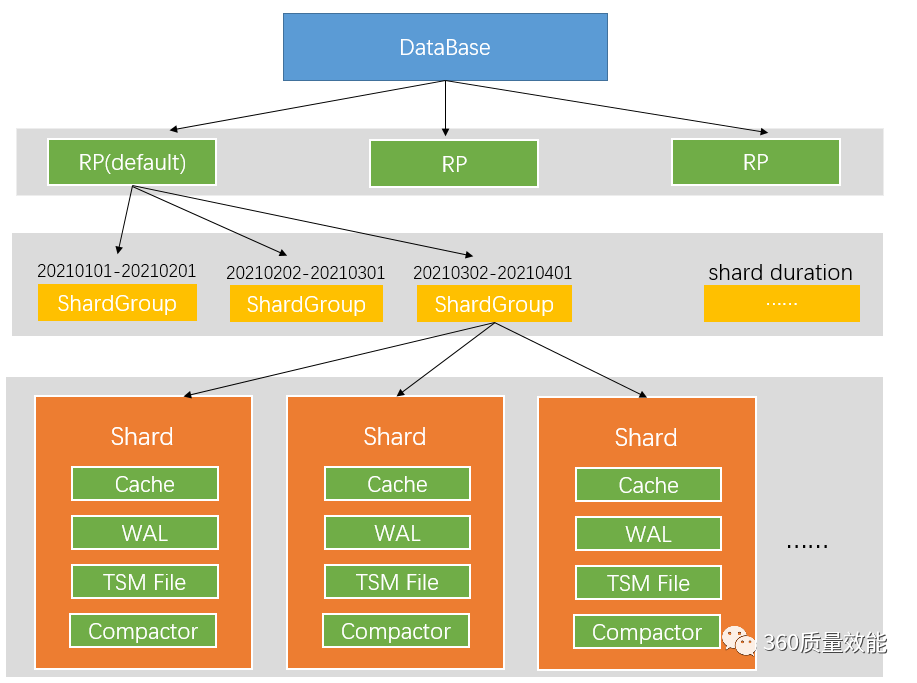
# 目录与文件结构
InfluxDB 的数据存储主要有三个目录。
默认情况下是 meta, wal 以及 data 三个目录。
meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件。
wal 目录存放预写日志文件,以 .wal 结尾。
data 目录存放实际存储的数据文件,以 .tsm 结尾。
# 四、InfluxDB下载与安装
# 1、windows安装(v1)
InfluxDB官方下载地址(v1):https://portal.influxdata.com/downloads/ (opens new window)
端口服务
8083:Web admin 管理服务的端口8086:HTTP API 的端口
运行
双击influxd.exe之后,再双击influx.exe。
上面的命令窗口就可以操作influxdb了;
也可以通过http://127.0.0.1:8083,访问图形化UI。
其中8083是influxdb.conf文件中admin部分bind-address所指定的,在浏览器中输入这个地址即可实现图形化的访问。
# 2、linux安装(v1)
# ubtuntu下载
wget https://dl.influxdata.com/influxdb/releases/influxdb_1.5.2_amd64.deb
sudo dpkg -i influxdb_1.5.2_amd64.deb
2
3
# centos下载
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.5.2.x86_64.rpm
sudo yum localinstall influxdb-1.5.2.x86_64.rpm
2
3
# 配置
安装后, 在/usr/bin下面有如下文件:
| 文件名称 | 描述 |
|---|---|
| influxd | influxdb服务器 |
| influx | influxdb命令行客户端 |
| influx_inspect | 查看工具 |
| influx_stress | 压力测试工具 |
| influx_tsm | 数据库转换工具(将数据库从b1或bz1格式转换为tsm1格式) |
在 /var/lib/influxdb/下面会有如下文件夹:
| 文件夹名称 | 描述 |
|---|---|
| data | 存放最终存储的数据,文件以.tsm结尾 |
| meta | 存放数据库元数据 |
| wal | 存放预写日志文件 |
配置文件路径 :/etc/influxdb/influxdb.conf
对应配置详情说明:配置说明
# 启动
以服务方式启动
sudo service influxdb start
/
sudo systemctl start influxdb
2
3
以非服务方式启动
influxd
需要指定配置文件的话,可以使用 --config 选项,具体可以help下看看。
# 3、基于 Docker 安装(v1)
docker-compose.yml
version: "3"
services:
influxdb:
image: influxdb:1.7.11
container_name: influxdb
restart: always
volumes:
- ./conf:/etc/influxdb
- ./data:/var/lib/influxdb/data
- ./meta:/var/lib/influxdb/meta
- ./wal:/var/lib/influxdb/wal
ports:
- "8083:8083" #8083是influxdb的web管理工具端口
- "8086:8086" #8086是influxdb的HTTP API端口
environment:
INFLUXDB_ADMIN_USER: root
INFLUXDB_ADMIN_PASSWORD: 123456
#启用身份验证。必须设置此设置
INFLUXDB_HTTP_AUTH_ENABLED: "true"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 五、InfluxDB客户端安装(v1)
可视化客户端安装:
客户端为绿色版,下载解压打开即可。下载地址:Releases · CymaticLabs/InfluxDBStudio
InfluxDBStudio下载地址 (opens new window)
安装教程:
这里也提供 InfluxDB Studio 的使用说明,供大家参考:
InfluxDB Studio 的使用说明 (opens new window)
# 六、InfluxDB操作(v1)
InfluxDB提供多种操作方式:
1)客户端命令行方式
2)HTTP API接口
3)各语言API库
4)基于WEB管理页面操作
# 1、客户端命令行方式操作
进入命令行
influx -precision rfc3339
# InfluxDB用户管理
#显示用户
show users
#创建用户
create user "username" with password 'password'
#创建管理员权限用户
create user "username" with password 'password' with all privileges
#删除用户
drop user "username"
# InfluxDB数据库操作
· 显示数据库
show databases
#新建数据库
create database shhnwangjian
#删除数据库
drop database shhnwangjian
#使用指定数据库
use shhnwangjian
# InfluxDB数据表操作
在InfluxDB当中,并没有表(table)这个概念,取而代之的是MEASUREMENTS。
MEASUREMENTS的功能与传统数据库中的表一致,因此我们也可以将MEASUREMENTS称为InfluxDB中的表。
InfluxDB 属于时序数据库,其着重考虑插入、查询,没有提供修改和删除数据的方法。
#显示所有表
show MEASUREMENTS
#新建表
InfluxDB中没有显式的新建表的语句,只能通过insert数据的方式来建立新表。
insert disk_free,hostname=server01 value=442221834240i
其中 disk_free 就是表名,hostname是索引(tag),value=xx是记录值(field),记录值可以有多个,系统自带追加时间戳。
或者添加数据时,自己写入时间戳
insert disk_free,hostname=server01 value=442221834240i 1435362189575692182
#删除表
drop measurement disk_free
# 存储策略(Retention Policies)
InfluxDB是没有提供直接删除数据记录的方法,但是提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据。
#查看当前数据库Retention Policies
show retention policies on "db_name"
默认的存储策略为autogen,数据保留时长0代表无限制,表示为永久保存。
#创建新的Retention Policies
create retention policy "rp_name" on "db_name" duration 3w replication 1 default
rp_name:策略名;
db_name:具体的数据库名;
shardGroupDuration:shardGroup的存储时间,shardGroup是InfluxDB的一个基本储存结构,应该大于这个时间的数据在查询效率上应该有所降低。3w:保存3周,3周之前的数据将被删除,influxdb具有各种事件参数,比如:h(小时),d(天),w(星期);
replication 1:全称是REPLICATION,副本个数,一般为1就可以了;
default:设置为默认策略
注意:
一个库中只允许一个默认策略,设置这个上一个默认的就会变成false。
如果有自己的策略,查询时measurement前带策略名,表示查这个策略的measurement,否则没有值。在insert时也要指定策略,否则查不到。
#修改Retention Policies
alter retention policy "rp_name" on "db_name" duration 30d default
#删除Retention Policies
drop retention policy "rp_name" on "db_name"
# 2、HTTP API接口
# 接口地址
| 接口路径 | 描述 |
|---|---|
| /debug/pprof | debug 排查问题使用 |
| /debug/requests | 使用这个请求监听最近是否有请求 |
| /debug/vars | 查询 influxdb 收集到静态信息 |
| /ping | 检测 influxdb 状态 |
| /query | 查询数据接口(同时可以创建 ku) |
# 状态码
| 状态码 | 说明描述 |
|---|---|
| 2xx | 服务请求正常 |
| 4xx | 代表请求语法有问题 |
| 5xx | 服务端出问题,导致超时等故障 |
# 七、InfluxDB函数(v1)
influxdb函数分为聚合函数,选择函数,转换函数,预测函数等。
除了与普通数据库一样提供了基本操作函数外,还提供了一些特色函数以方便数据统计计算,下面是其中一些常用的特色函数。
- 聚合函数:FILL(), INTEGRAL(),SPREAD(), STDDEV(),MEAN(), MEDIAN()等。
- 选择函数: SAMPLE(), PERCENTILE(), FIRST(), LAST(), TOP(), BOTTOM()等。
- 转换函数: DERIVATIVE(), DIFFERENCE()等。
- 预测函数:HOLT_WINTERS()。
| 聚合Aggregations | 选择Selectors | 转换Transformations |
|---|---|---|
| COUNT() | BOTTOM() | CEILING() |
| DISTINCT() | FIRST() | DERIVATIVE() |
| INTEGRAL() | LAST() | DIFFERENCE() |
| MEAN() | MAX() | ELAPSED() |
| MEDIAN() | MIN() | FLOOR() |
| SPREAD() | PERCENTILE() | HISTOGRAM() |
| SUM() | TOP() | MOVING_AVERAGE() |
| NON_NEGATIVE_DERIVATIVE() | ||
| STDDEV() |
详情:
# 八、连续查询(v1)
# 定义
InfluxDB 的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含 SELECT关键词和GROUP BY time()关键词。InfluxDB 会将查询结果放在指定的数据表中。
连续查询与SQL数据库中的存储过程类似。
# 目的
使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低 InfluxDB 的系统占用量。
而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
# 操作
只有管理员用户可以操作连续查询。
1)新建连续查询
新建连续查询的语法如下所示:
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
[RESAMPLE [EVERY <interval>] [FOR <interval>]]
BEGIN SELECT <function>(<stuff>)[,<function>(<stuff>)] INTO <different_measurement>
FROM <current_measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<stuff>]
END
2
3
4
5
查询部分被 CREATE CONTINUOUS QUERY […] BEGIN 和 END 所包含,主要的逻辑代码也是在这一部分。
使用示例:
> CREATE CONTINUOUS QUERY cq_30m ON telegraf BEGIN SELECT mean(used) INTO mem_used_30m FROM mem GROUP BY time(30m) END
> SHOW CONTINUOUS QUERIES
name: telegraf
--------------
name query
cq_30m CREATE CONTINUOUS QUERY cq_30m ON telegraf BEGIN
SELECT mean(used) INTO telegraf."default".mem_used_30m FROM telegraf."default".mem
GROUP BY time(30m) END
name: _internal
---------------
name query
2
3
4
5
6
7
8
9
10
11
12
13
示例在 telegraf 库中新建了一个名为 cq_30m 的连续查询,每三十分钟取一个 used 字段的平均值,加入 mem_used_30m 表中。使用的数据保留策略都是 default。
2)显示所有已存在的连续查询
查询所有连续查询可以使用如下语句:
> SHOW CONTINUOUS QUERIES
name: telegraf
--------------
name query
cq_30m CREATE CONTINUOUS QUERY cq_30m ON telegraf
BEGIN SELECT mean(used) INTO telegraf."default".mem_used_30m FROM telegraf."default".mem
GROUP BY time(30m) END
name: _internal
---------------
name query
2
3
4
5
6
7
8
9
10
11
12
可以看到其连续查询的名称以及 语句等信息。
3)删除 Continuous Queries
删除连续查询的语句如下:
DROP CONTINUOUS QUERY <cq_name> ON <database_name>
# 其他说明
在 InfluxDB 中,将连续查询与数据存储策略一起使用会达到最好的效果。
比如,将精度高的表的存储策略定为一个周,然后将精度底的表存储策略定的时间久一点,这要就可以实现高低搭配,以满足不同的工作需要。
# 九、Java集成Influx DB(v1)
官方提供目前只提供了通过http api访问数据库的方式。我们用GitHub上的开源框架与数据库进行交互。
项目地址为:https://github.com/influxdata/influxdb-java (opens new window)
This is the official (and community-maintained) Java client library for InfluxDB (1.x), the open source time series database that is part of the TICK (Telegraf, InfluxDB, Chronograf, Kapacitor) stack.
Note: This library is for use with InfluxDB 1.x. For connecting to InfluxDB 2.x instances, please use the influxdb-client-java client.
# Pom依赖
pom引入依赖
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>2.18</version>
</dependency>
2
3
4
5
# 主要实现类
# InfluxDBFactory
InfluxDBFactory是一个工厂类,可以通过如下方式返回一个InfluxDB的实例
InfluxDB influxDB = InfluxDBFactory.connect("http://localhost:8086", "username", "password");
# Point
相当于关系型数据库中的一行数据,因为此类数据库一行数据在图中一般显示为一个点,故为Point,可以此类添加行数据,如tag(索引列)field(普通列)
# Query
通过要执行的SQL和数据库名构造Query对象,作为参数传递到InfluxDBImpl类的查询方法中,即可返回一个QueryResult对象,里面封装了查询生成的数据。
# QueryResult
这个类比较复杂
public class QueryResult {
private List<Result> results;
private String error;
public static class Result {
private List<Series> series;
private String error;
}
public static class Series {
private String name;
private Map<String, String> tags;
private List<String> columns;
private List<List<Object>> values;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
其中Result和Series为QueryResult的内部类,嵌套比较深,取数据比较麻烦,取数据的方法大都类似于
Object obj = queryResult.getResults().get(0).getSeries().get(0).getValues().get(0).get(1);
# InfluxDBMapper
InfluxDBMapper实现了InfluxDB接口,提供了对数据库操作的基本方法,如新建数据库,删除数据库,插入数据,查询数据等。
InfluxDBMapper influxDBMapper = new InfluxDBMapper(influxDB);
Query query = new Query(command, this.database);
return influxDBMapper.query(query, clazz);
InfluxDBMapper influxDBMapper = new InfluxDBMapper(influxDB);
influxDBMapper.save(model);
2
3
4
5
6
# InfluxDBResultMapper
可以通过如下方式将查询结构映射到一个Bean中
InfluxDBResultMapper resultMapper = new InfluxDBResultMapper();List<NewBean> cpuList = resultMapper.toPOJO(queryResult, NewBean.class);
其中NewBean是一个POJO类。
注意事项
通过StringBuilder拼接SQL语句,进行查询,注意不能单独查询tag列,必须有一个field列。
# 配置InfluxDBFactory
# 实体类添加注解
# @Measurement(name="warn")
用于标识Measurement ——表名
package org.influxdb.annotation;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Measurement {
String name();
String database() default "[unassigned]";
String retentionPolicy() default "autogen";
TimeUnit timeUnit() default TimeUnit.MILLISECONDS;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
name 表名
database 库名
retentionPolicy 存储策略,默认永久
timeUnit 时间单位,默认毫秒
# @TimeColumn
用于标识Timestamp——时间戳
# @Column(name = "", tag=true)
用于标识filed或者tag
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Column {
String name();
boolean tag() default false;
}
2
3
4
5
6
7
8
name filed属性
tag 标识是否为带索引的属性,默认为false
@Measurement(name = "cpu",database="servers", retentionPolicy="autogen",timeUnit = TimeUnit.MILLISECONDS)
public class Cpu {
@Column(name = "time")
private Instant time;
@Column(name = "host", tag = true)
private String hostname;
@Column(name = "region", tag = true)
private String region;
@Column(name = "idle")
private Double idle;
@Column(name = "happydevop")
private Boolean happydevop;
@Column(name = "uptimesecs")
private Long uptimeSecs;
// getters (and setters if you need)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 官方使用示例
QueryBuilder (opens new window)
例1:根据条件查询
Query query = select().from(DATABASE,"h2o_feet").where(gt("water_level",8));
例2:查询count
Query query = select().count("water_level").from(DATABASE,"h2o_feet")
.where(eq("location","coyote_creek"))
.and(gte("time","2015-08-18T00:00:00Z"))
.and(lte("time","2015-08-18T00:30:00Z'"))
.groupBy(time(12l,MINUTE));
2
3
4
5
6
7
8
9
例3:通过sql语句查询
Query query = new Query("SELECT * FROM h2o_feet");
# InfluxDBMapper
influxdb-java-2.18 (opens new window)
Query query = ... create your queryList<Cpu> persistedMeasure = influxDBMapper.query(query,Cpu.class);
# 十、补充扩展知识
# 双引号单引号问题
influxdb数据库字符串类型,使用双引号查不出数据,单引号可以。
插入数据时,字符串类型要是用双引号,单引号报错。
# 时区问题
另外influxdb还有时区的问题,他默认使用的是UTC时区,和中国差了8小时。
# 动态传入@Measurement的名称
由于业务需要“灵活可配置”的功能需求,在使用java开发Influxdb查询功能的时候,遇到了一个问题,Measurement注解的名称有可能需要动态变化。
问题可以转换为:
在@Measurement 注解生效之前,将变动的name值写入。
解决:
使用java反射去解决,主要需要操作以下两个类的api:
java.lang.reflect.InvocationHandler;
java.lang.reflect.Proxy;
2
3
最终解决方案,通过继承 InfluxDBResultMapper 的 toPOJO 方法得以解决。
以下贴出代码:
public class InfluxDBResultMapperHelper extends InfluxDBResultMapper {
public <T> List<T> toPOJO(final QueryResult queryResult, final Class<T> clazz,String name)
throws InfluxDBMapperException {
InvocationHandler handler = Proxy.getInvocationHandler(clazz.getAnnotation(Measurement.class));
Field hField = null;
try {
hField = handler.getClass().getDeclaredField(ME_VALUE);
hField.setAccessible(true);
Map memberValues = (Map) hField.get(handler);
memberValues.put(ME_NAME, name);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return toPOJO(queryResult, clazz, TimeUnit.MILLISECONDS);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 相关资料
InfluxDB GitHub地址 (opens new window)
InfluxDB官方下载地址(v1):https://portal.influxdata.com/downloads/ (opens new window)
influxdata client API 官方文档 (opens new window)